
Iron.io @ Big Data Hack Day
![]() Iron.io is putting in some time at the Big Data Hack Day this weekend in San Francisco. A number of teams working with a number data sets to solve some hard challenges.
Iron.io is putting in some time at the Big Data Hack Day this weekend in San Francisco. A number of teams working with a number data sets to solve some hard challenges.
The event was put on by the AngelHack and Hackathon.io folks and had a concentrated set of sponsors, all suited to working out problems with collecting and processing large volumes of data. In addition to Iron.io, there were folks from Couchbase and Firebase (and Google Cloud Platform and Prior Knowledge).
 |
| Big Data Hack Day Sponsors (partial list) |
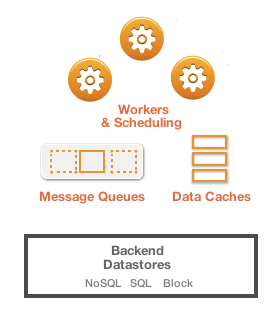
The pairing of Iron.io's services (IronWorker, IronMQ, and IronCache) with back-end datastores – in the case of Couchbase, a fast NoSQL document database and in the case of Firebase, a real-time hosted datastore – makes a ton of sense. Workers, message queues, data caches, and job scheduling provide a asynchronous processing and orchestration tier that lets developers collect, process, transform, post, publish, and distribute data without having to exclusively work in particular paradigms (map-reduce as one example).
 |
| Async Processing Tier + Backend Datastore |