
Web Crawling at Scale with Nokogiri and IronWorker (Part 1)

This is a two-part post focusing on using Nokogiri and IronWorker to crawl websites and process web pages. Part two can be seen here. For other resources on web crawling, see our solutions page as well as this in-depth article on using IronWorker with PhantomJS.
Web crawling is at the core of many web businesses. Whether you call it web crawling, web or screen scraping, or mining the web, it involves going to sites on the web, grabbing pages, and parsing them to pull out links, images, text, prices, titles, email addresses, and numerous other page attributes.

But extracting items from pages is just
the start, though. After getting this data, it often needs to get processed, transformed, aggregated, posted, or manipulated. It could be to pull out the right image to display alongside an article blurb or to create some derivative values for use with content or opinion mining.
Crawling and processing can happen over a handful of sites that are regularly monitored or it could be done across thousands of sites. The combination of IronWorker, IronMQ, and IronCache is well suited for scheduling, orchestrating, and scaling out this type of work.
Nokogiri At a Glance
Nokogiri is the principal gem that Ruby developers use for parsing HTML pages. The reasons are pretty simple – it provides a comprehensive offering with many features, supports a wide variety of HTML and XML parsing strategies (DOM, SAX, Reader and Pull), has an enthusiastic community around it (which means easier support and greater enhancements), and offers good performance.
Using Nokogiri within an application or worker is pretty simple. Just download the gem, require it a worker file, and then create a Nokogiri instance. Included below is a code sample. This is part of a page processing worker within the larger web crawling example that you can find on Github at the link below.

Example Repo: Web Crawler – Nokogiri
The Page Processor worker below gets passed a set of page URLs and then goes through them in sequence to pull out a number the page attributes. Nokogiri takes an IO object or a String object as part of the instantiation. In this example, we use ‘open-uri’ and pass it a URL.
Filename: page_processor.rb (excerpt)
require ‘open-uri’
require ‘nokogiri’
def process_page(url)
doc = Nokogiri(open(url))
images, largest_image, list_of_images = process_images(doc)
links = process_links(doc)
css = process_css(doc)
words_stat = process_words(doc)
end
Above is the main procedure for extracting items in a page. Below are the procedures to pull out the various page attributes using Nokogiri calls:
def process_images(doc)
#get all images
images = doc.css(“img”)
#get image with highest height on page
largest_image = doc.search(“img”).sort_by { |img| img[“height”].to_i }[-1]
largest_image = largest_image ? largest_image[‘src’] : ‘none’
list_of_images = doc.search(“img”).map { |img| img[“src”] }
return images, largest_image, list_of_images
end
def process_links(doc)
#get all links
links = doc.css(“a”)
end
def process_css(doc)
#find all css includes
css = doc.search(“[@type=’text/css’]”)
end
def process_words(doc)
#converting to plain text and removing tags
text = doc.text
#splitting by words
words = text.split(/[^a-zA-Z]/)
#removing empty string
words.delete_if{|e| e.empty?}
#creating hash
freqs = Hash.new(0)
#calculating stats
words.each { |word| freqs[word] += 1 }
freqs.sort_by {|x,y| y }
end
Nokogiri – Deeper Dive
The full example on Github has a bit more sophistication to it (using IronCache to store the items collected for use by other workers). For a deeper dive on Nokogiri check out these tutorials here, here, and here and a great RailsCast here.
Crawling at Scale with IronWorker
Having a code library for crawling and parsing pages, however, is only one part of the equation for doing any amount of significant work. To crawl web pages at scale, there needs to be some effort behind the scenes to both gain enough compute power to handle the load as well as smoothly orchestrate all the parts within the process.
This is where Iron.io and IronWorker come in. By adding an elastic task queue to the mix, developers get the ability to scale page processing up and down without having to deal with servers, job queues, or other infrastructure concerns. A scalable task queue also lets developers distribute the work across thousands of cores. This not only provides compute power that developers can’t easily achieve on their own, but it also will significantly reduce the duration of crawls (in some cases by 10x or even 100x).
Two Stage Process: Web Crawling ➞ Page Processing
Web crawling at scale means structuring your code to handle specific tasks in the operation. This makes it easier to distribute the work across multiple servers as well as create an agile framework for adding and expanding functionality. The base structure is to create two types of workers – one to crawl sites to extract the page links and another to process the pages to pull out the page attributes. By separating these tasks, you can focus attention on the resources and logic around site crawling workers separate from the resources and logic around page processing.
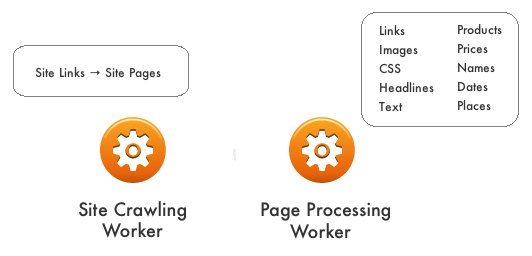 |
| Separate Workers – Separate Functions |
The goal of the design is so each worker can operate as independently and as stateless as possible. Each worker should be specific to a task as well as designed to process a finite amount of data. In this way, you’ll be able to distribute the workload by activity as well as by portion. For site crawling, workers can start with the head of a site and then spawn off workers to handle sections or page-level depths as needed to distribute the load.
For page processing, workers can be designed to handle a certain number of pages. The reason is so that you can scale the work horizontally without any additional effort just by queuing up new tasks and passing in a list of pages. (In the full example and in part 2 of the blog post, we show how a message queue can help orchestrate the effort).
Queuing up Workers
Once the general structure of the workers has been created, it’s a relatively simple matter to put web crawling at scale into motion. With an elastic task queue, it’s primarily the case of queuing up workers to run. The processing and distributing the workload across servers is handled automatically by IronWorker.
@iron_worker_client.tasks.create(“WebCrawler”, p)
The components that you include when queuing a worker includes the name of the worker and a payload. Optional items such as priority, timeout, and delay can also be included.
An example might be to run a WebCrawler task at a higher priority (p1) and with a 30 minute timeout.
@iron_worker_client.tasks.create(“WebCrawler”, p, {:priority => 1}, {:timeout => 1800}
One thing to note is you need to upload your workers to IronWorker. Once it’s in the cloud, apps can spin up as many tasks as it needs. (Upload once, run many.)
 |
| API Spec for Queuing a Task |
Managing the Workload: Task Duration and Visibility
The amount of processing each worker should be long enough in length to amortize the setup cost of a worker but not so long as to limit the ability to distribute the work. We generally encourage web crawling and page processing tasks that run in minutes as opposed to seconds. Somewhere on the order of 5-20 minutes appears to be the sweet spot based on the data we’ve been able to collect. (IronWorker has a 60-minute task limit.)
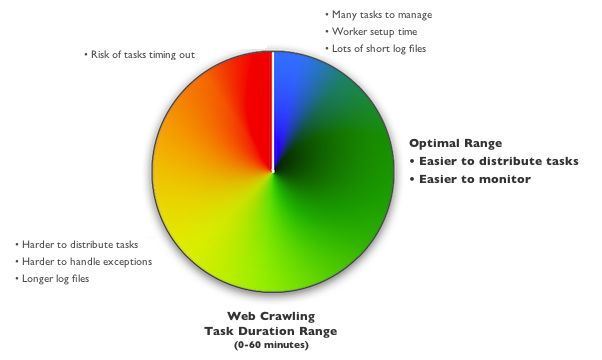
One factor that plays into optimal task duration is the human element of monitoring tasks. Having to scroll through tons of 4-second tasks can be difficult. Same with looking at the log files of long running tasks. There’s no hard and fast rule but if you construct workers to handle varying amounts of work, then you can then find the right fit that lets you distribute the workload efficiently as well easily monitor the set of tasks. Below is a view of the IronWorker dashboard and how it can help you keep track of everything that’s happening with a particular project.
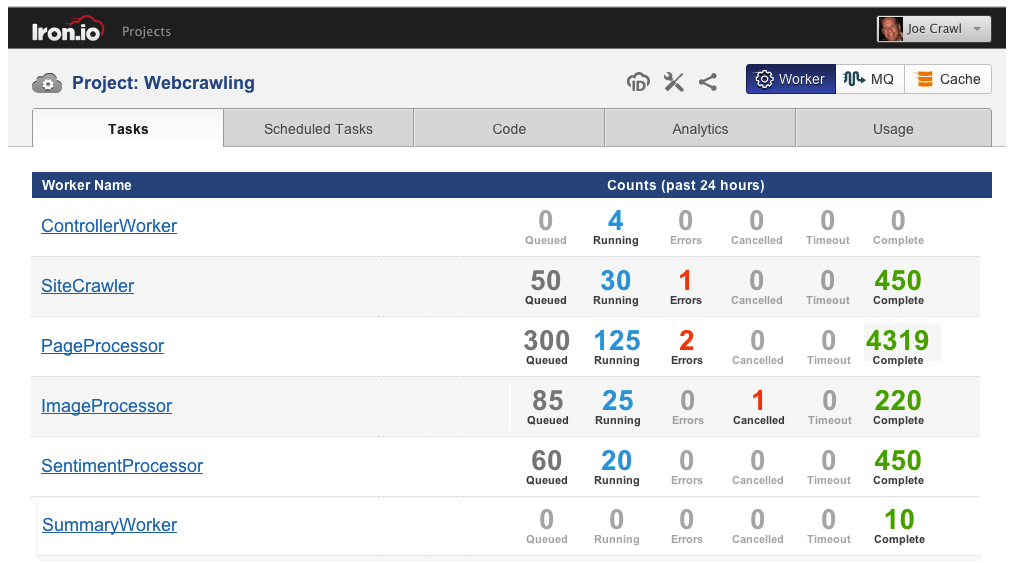 |
| IronWorker Dashboard |
More Extensive Web Crawling
To extend the approach, you can build in master or control workers as well as workers to do even more detailed processing on the extracted data. You can also add in workers to aggregate some of the details after a crawling cycle has completed.
The advantages of task-specific workers is that they don’t necessarily have to impact the operation of any of the other workers. This allows a system to be extended much quickly and easily than something that’s more tightly bound up within an application framework.
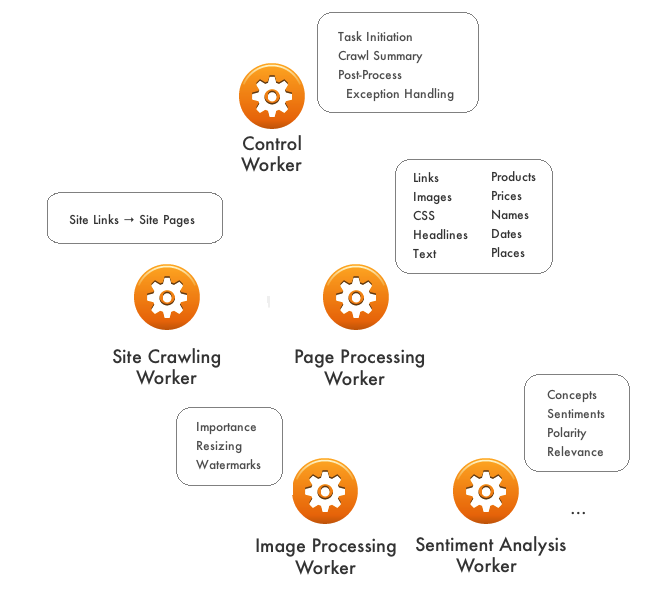 |
| Add Additional Workers to Extend Capabilities |
The process of orchestrating these tasks is made easier by other IronWorker features such as scheduling and max_concurrency as well as by using IronMQ to create the right flow between processes and IronCache to provide easy ways to share state and store global data – features and services that we’ll address in Part 2.
The combination of Nokogiri, one of the top HTML parsers, and IronWorker, an elastic task queue, provide a great combination for getting a lot of crawling done. Add in the other capabilities above and you have a platform that would have been out of reach for most teams just a few years ago.
For a deeper look at crawling at scale, take a look at the example at the link below.
Example Repo: Web Crawler – Nokogiri
Notes on Web Crawling Etiquette
- Crawl sites only with some form of approval, adherence to stated policy, and/or good judgement.
- Make use of APIs for accessing data if they’re available.
- Take a look at a site’s robots.txt file.
- Check out StackOverflow for articles like this one and this one.