
IronMQ Enterprise: Powered by IronMQ v3
Table of Contents
ToggleDelivering Improved Performance + On-Premise and Hybrid Cloud Options
Today we announced IronMQ Enterprise, a set of offerings that includes more flexible configuration options including deployment on-premise and within private clouds as well as improved performance around message throughput and latency.
 At the heart of this release is IronMQ v3, our latest version of IronMQ. A lot of work went on behind the scenes to improve the core messaging engine and so we wanted to use this post to give you some of the details on the efforts of the Iron.io team.
At the heart of this release is IronMQ v3, our latest version of IronMQ. A lot of work went on behind the scenes to improve the core messaging engine and so we wanted to use this post to give you some of the details on the efforts of the Iron.io team.
A good part of the effort on IronMQ v3 was focused on improving the backend persistence layer. Persistence is a key requirement within any production-scale messaging solution. If a server or the message queue goes down, you don’t want messages to be lost. With some message queues, however, especially open-source versions, message persistence has to be configured at some considerable cost and can entail some serious performance hits.
IronMQ offers persistence by design – meaning we don’t offer it in non-persistent form. As a result, the persistent storage layer receives a lot of attention and is something we make significant efforts to get right. In addition to the work on persistence, other efforts that went into IronMQ v3 included changes to the authentication layer as well as improvements to our APIs. All this work resulted in solid performance improvements along with greater ease of deployment and operation. In the end, we share some of the performance comparisons against RabbitMQ.
Achieve Cloud Elasticity with Iron
Speak to us to find how you can achieve cloud elasticity with a serverless messaging queue solution with free handheld support.
Improved Backend Persistence Layer
IronMQ v3 moves to a modular format that can make use of embeddable key/value databases for the backend persistence layer, replacing the prior version that had been based on a NoSQL database implementation. The evaluation version uses RocksDB, an embeddable open-source key/value database that is a fork of LevelDB. The move to this type of key/value database provides a persistence layer that is far better suited to the needs of message queuing and the deployment needs of distributed cloud technologies. A few of these benefits include:
Read/Write Optimizations
 |
| A Key/Value DB is Better Suited for MQs |
The read-write patterns for a queue are different than most other transactional or data storage use cases. The most common queue pattern is generally write once, read once, and then delete. While additional metadata gets stored and additional accesses go on behind the scenes, the pattern of messages in and messages out, does mean a continual recycling of data around limited durations. A key/value database handles frequent deletions more gracefully than our prior NoSQL solution, performing cleanup in multiple background threads thereby giving live traffic little to no performance degradation. The key/value database also uses lookup optimization to reduce the time for most “get” operations and is further optimized in conjunction with a large in-memory cache.
Locking Optimizations
 |
| Improved Read/Writes Reduce Locks |
The IronMQ v3’s database layer is logically partitioned into a read-only path, a read-write path plus its write patterns scale concurrently across queues. The separate paths and concurrent writes drastically reduces the number of locks on write operations that are critical for supporting high throughput transactions. Whereas the database guarantees atomicity and durability, we added our own level of granularity on top of the database to provide locking for guarantees such as FIFO, one-time message delivery, and other consistent operations. This means we can optimize our locks on a per queue basis, thereby taking advantage of the write concurrency to avoid unnecessary locks on unrelated queues.
Storage Optimizations
 |
| An Optimized DB Means Faster Data Access |
Multicore servers and new storage options such as SSD flash drives are allowing storage-IOPS on the order of millions of requests per second. Database driver software that can make use of the IOPS offered by flash storage can perform much faster than unoptimized DBs across random read, write, and bulk uploads. The switch to a more modern key/value database provides greater upside for gains on write workload, bulk uploads, as well as pure random read workload. Multi-threaded compaction processes can also provide gains over single-threaded processes IO-bound workloads, translating into fewer write-stalls and more consistent latency.
Streamlined Authentication Access
 |
| An Embedded AuthDB Reduces Latency |
Iron.io v3 also contains streamlined authentication. IronMQ is a multi-tenant message queue that uses HTTP/REST-protocols and OAuth authentication. API operations get authenticated, which means there is overhead to either the AuthDB or cache for every operation. The same improvements to the backend persistence layer described above were also made for the auth componentry within IronMQ v3. Namely, the prior database was replaced with an efficient key/value store which means that it also inherits the same performance characteristics, which means not just reduced auth overhead but also greater consistency in response times. The change within the auth access layer also includes a more modular architecture which provides an easier ability to support additional non-OAuth access methods such as PKI signatures.
IronMQ and HTTP/REST APIs
One thing to highlight here is that IronMQ Enterprise uses HTTP as the transport protocol for connecting to the service. This is in contrast to RabbitMQ which uses AMQP. We believe there are distinct advantages in using HTTP. One of the more pressing reasons to favor HTTP over AMQP is that AMQP is a separate application layer protocol than the one developers are used to using plus it has a significant amount of complexity to it. Everyone can easily speak HTTP, but it takes a special effort to speak AMQP. Another distinction is that certain cloud application hosts don’t allow socket connections to and from their virtual environments but they do allow HTTP requests. Additionally HTTP and HTTPS are always open on most enterprise firewalls, but special ports for AMQP may not be. You can read more of our reasons to favor HTTP over AMQP here.
Iron.io Serverless Tools
Speak to us to learn how IronMQ is an essential product for your application to become cloud elastic.
Thanks for subscribing! Please check your email for further instructions.
APIs Modifications | Support for Other Messaging Protocols
 |
| Improved HTTP/REST API Consistency |
The process of upgrading to IronMQ v3 also allowed us to make changes to the IronMQ APIs to accommodate learnings from users and their use of a cloud-native message queue. The HTTP/REST calls didn’t change drastically but we were able to address a few idiosyncrasies of the prior API structure as well as introduce greater consistency within the command set.
One of the changes to the API includes changing the IronMQ ‘get’ operation from an HTTP GET to an HTTP POST operation to be consistent with REST conventions. Another change is the introduction of a reservation ID when getting a message that must be used upon deleting a message so as to avoid race conditions (which can occur when a message times out but is still in use by the client).
Developers should not see any real difference in the APIs as most users make use of client libraries to interface with the service. (The client libraries add an abstraction layer to the APIs to make it easier to use the service within a specific language or app framework.) The use of IronMQ v3 does require the use of v3 specific client libraries, which you can find available on GitHub.
More Flexible Protocol Support
 |
| Improved API Gateways Enhance Protocol Support |
Also included alongside the API modifications is the inclusion of gateways to support other protocols such as AWS SQS protocol and OpenStack Marconi protocol. SQS is a popular message queuing service provided by Amazon that uses proprietary approaches for authentication and API commands. Marconi is a cloud messaging service project within OpenStack. (Iron.io participated and assisted in developing the specification. IronMQ is compatible with almost all the features of both services. The more flexible gateway in IronMQ v3 allows easier support of these two messaging protocols.
IronMQ v3 – A Better Cloud MQ
Our development team put in hard work into improving IronMQ and releasing IronMQ Enterprise. This work has paid off with solid performance gains, simpler componentry, and elimination of outside dependencies. The result is a fully-featured but very tight high-performance messaging solution that can be more easily deployed in high availability configurations across clouds.
Downloading IronMQ v3
IronMQ is written in Go. A single server evaluation version can be installed from binary files or as a Docker image from here: ironio.staging.wpengine.com/mq-enterprise.
The IronMQ single server evaluation version is free to use, installs in minutes, and provides message persistence, multi-tenancy, one-time guaranteed delivery, and the same features, capabilities, and access methods that can be found in the public cloud version of IronMQ.
Performance Measurements
IronMQ vs RabbitMQ
The work described above has resulted in significantly higher throughput for writes as well as performance increases for reads over prior versions of IronMQ.
Below are performance tests for IronMQ and RabbitMQ. We chose RabbitMQ as a base comparison given how popular and well-established RabbitMQ is. The results are indicative of the performance characteristics of IronMQ v3.
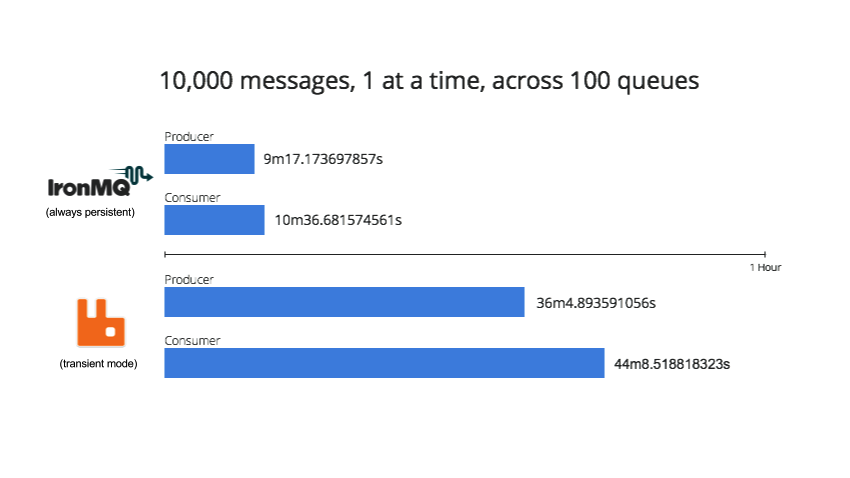
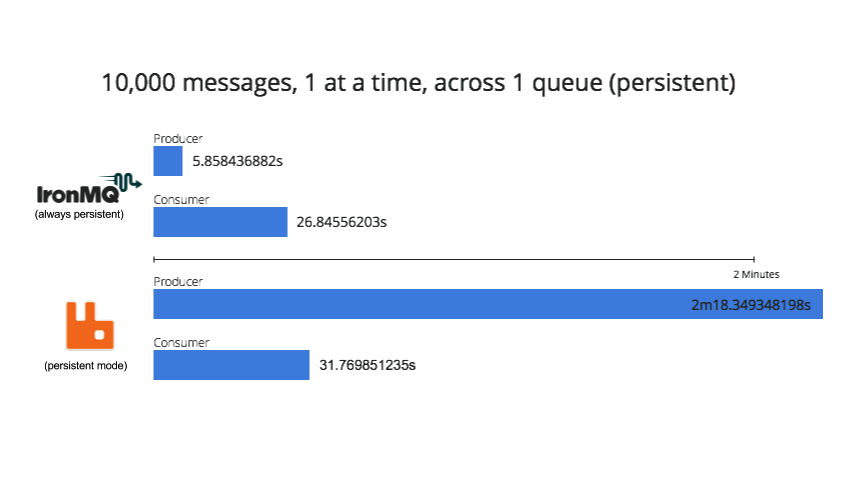
A total of 5 tests were performed. The first 4 tests were performed in “transient” mode for RabbitMQ, meaning no message persistence – all messages exist only in memory. The last test was performed in “persistent” mode for RabbitMQ. Note that performance drops significantly in this mode. IronMQ is always persistent (meaning that messages are persisted to disk and there cannot be lost in the event of a server or MQ crash).
Test Specifications
The code for the test suite can be found at github.com/rdallman/iron-maiden
- Both RabbitMQ and IronMQ were run on separate AWS m3.2xlarge boxes with the following specs:
- 8 vCPU clocked at 2.5GHz
- 30 GB RAM
- 2 x 80 GB SSD storage
- Databases for each MQ were cleared before each benchmark
- Producers and consumers ran on a single AWS m1.small box in the same datacenter
- Each message body was a 639-character phrase
- 4 tests were performed in “transient” mode for RabbitMQ (no persistence)
- 1 test was performed in “persistent” mode for RabbitMQ (resulting in performance hits)
Processing 1 Message at a Time (1 message per API request)

Processing 100 Messages per at a Time (100 messages per API request)

Processing 100 Messages at a Time w/Single Consumer/Producer

Processing 10,000 Messages per Queue, 100 Queues, 1 Message at a Time,
Processing 1 Message at a Time with Persistence Turned on for RabbitMQ
Future Benchmarks
We’re doing more benchmarks against other MQs and configurations and so stay tuned. For now, though, we’re celebrating a bit and then we’re getting back to work. There’s a lot more performance we believe we can squeeze out.
 |
| Salud! |
Unlock the Cloud with Iron.io
Find out how IronMQ can help your application obtain the cloud with fanatical customer support, reliable performance, and competitive pricing.