
The Workloads of the Internet of Things
I must say my favorite part about researching the Internet of Things has to be the mind blowing stats. Just a couple from the arsenal… we already have more connected devices on the planet than humans, and every two days we create more data than all of human history up to 2003. The predictions are wild too… Intel predicts that there will be 200 billion connected devices by 2020, and Cisco predicts the market size to reach $14.4 Trillion by 2022. It’s hard to really wrap your head around numbers like that, but there was one that really jumped out at me – IDC predicts that Internet of Things workloads will increase approximately 750% by 2019. Why that really matters: how on earth are we going to handle that level of scale?
We’re already busting at the seams with our capacity as-is, so this meteoric rise in IoT workloads will put even more pressure on the data centers providing the infrastructure resources, the telecoms providing the network, and the software companies providing the complementary platforms and services. Unless Google’s Actual Cloud becomes something more than an April Fool’s Joke, the entire cloud ecosystem will have to step up to not only provide the raw resources at massive scale, but also come up with fresh ways to distribute the workloads more efficiently.
The good news is that we’ve already come a long way as an ecosystem to address these challenges at scale head on. The rise of container technologies such as Docker, tightening our software components via the Microservices architectural style, and better code efficiency through more API-led development, have all reduced much of the waste in our resource consumption and software delivery models. Let’s take a look at some of these modern patterns to see if we can apply them to the growing volume of IoT workloads.
Turning Events into Insight
First things first, in order for the Business of the Internet of Things to matter, the key for developers and data scientists will be to figure out how to translate events generated from connected devices into insight that can be delivered via API through the transformation of data. Without actionable intelligence, the end user applications will be useless, and the devices themselves will be worth no more than face value. “A flute with no holes is not a flute. A donut with no hole… is a danish.”
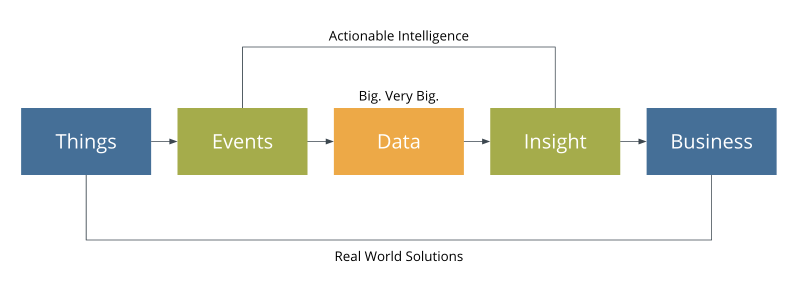
Extract Event, Transform, Load
We’re dealing with very big data here that’s being generated from a wide range of sources, in a variety of formats, speaking over different protocols. This places extra importance on the data transformation process. A common industry pattern over the years has been to create pipelines to extract data from sources, transform according to business logic, and load to destinations (ETL).
Where this pattern differs with IoT workloads is that we’re dealing with events that push, not extraction that pulls. This means that our workflows need to be event-driven, and automatically engage when triggered to get from source to destination.
Event-Driven Computing
What do we mean by “event-driven”? Technically speaking, everything that has happened in the entire universe since whatever happened before the Big Bang has been event-driven, so what’s the big idea? In computing, what we mean by event-driven is responding to changing environments automatically. Connected devices give us the ability to capture anything, anywhere, any time – but we need to be able to then act on it. That’s where event-driven computing comes into play.
Event triggers come in many forms, with sensors and actuators embedded on everything from our bodies to the planet (Paging the writers of Black Mirror). These events then kick off processes, whether it be a simple task or a chain of tasks. Once processing is complete, the contextual data is delivered to its subscriber endpoints, which could be an analytics dashboard, a mobile app, a running service, or a data warehouse to name a few. This whole process happens asynchronously.

Task-Centric Platform
Modern applications and the clouds that power them have come along way in recent years with the rise of the PaaS market. Heroku pioneered the concept of the 12-factor app, which has been adopted by modern Enterprise platforms such as Pivotal Cloud Foundry and OpenShift by Red Hat. Looking at the behavior of these event-driven workloads, however, we find ourselves in need of a different processing pattern that applies similar principles to tasks.
Applications vs. Tasks
First, let’s make a distinction between applications and tasks to understand the different behaviors (Note that I’m purposely leaving out Microservices here).
| Applications | Tasks |
| Hosted: Applications are always alive, running via web server* | Ephemeral: Tasks are only alive for the duration of the process |
| Load Balanced: Incoming traffic is routed via load balancer to available resources | Queued: Jobs are placed on a queue and dispatched to available resources** |
| Elastic: Scaling means adjusting nodes that start up and shut down | Concurrent: Scaling means running more processes within running nodes*** |
| Orchestrated: Workloads are dispatched via a central coordinator | Choreographed: Workloads are triggered by responding to events |
* Excluding native mobile applications
** The queue itself needs to be highly available and load balanced
*** Assuming capacity exists and is freely available for work
Some common examples of tasks could be filtering incoming data, transferring data, analytics processing, stream processing, multimedia encoding, transaction handling, workflow coordination, and alerting just to name a few. With this distinction clearly made, it’s safe to say that task-centric workloads will require a more task-centric platform environment. This is where Iron.io comes into play.
Powering IoT Workloads with Iron.io
Iron.io is an event-driven computing platform specifically designed for handling asynchronous workloads at scale. We’re not an “IoT Platform” per se, however the asynchronous nature of these types of workloads just so happens to fit right into our wheelhouse.
IronMQ is a cloud-native message queue service, meant for reliable data delivery across systems and services, and IronWorker is an asynchronous processing service, meant for powering tasks at scale. Together they are well suited for IoT workloads (I invented the term Task PaaS, but then said it out loud).
How it Works
To give a quick peek under the hood, here’s a simplified view of our stack. First, we provide native client libraries across most popular languages. This allows you to interface with the Iron.io API directly in the language right for the job.
Core running API services are the queue API, task scheduler and task prioritizer. These are the primary ways to manage the triggers and execution of your workloads.
At the heart is IronMQ, which is used here as both a standalone message queue, and as a task queue. By leveraging a message queue, task state is persisted, allowing you to manage failures by retrying tasks that errored out. The queue also acts as an intelligent dispatcher, distributing workloads to available compute resources.
The runtime environment consists of an independently running agent that is continually pulling tasks from the queue, spinning the code up in a fresh Docker container, executing the task, and then destroying the container. Rinse and repeat at massive scale. The task code itself is merged with the associated Docker image, which will provide basic language and library dependencies.
Where Iron.io Fits Within a Complete IoT Stack
There is no single “IoT Platform” despite the hype machine. An end-to-end IoT stack will be comprised of a number of components, connected together via API. The API layers will be crucial in getting data from devices to systems, and systems to applications. The entire stack must be wrapped with security and monitoring layers, and of course, data is continually crossing the network.
Iron.io fits in the systems layer, directly interfacing with the infrastructure and data stores to dispatch workflows and process the workloads. It is our goal to tightly integrate with the API components within the device layer and application layer, as well as make it easy to deploy our services within any cloud environment, public or private.
A Growing Ecosystem
It will be interesting to watch this IoT ecosystem play out as the wide range of real world solutions start to hit the streets (pun intended). Large players such as Intel, Cisco, GE, and IBM are investing heavily in the space, with relative newcomers such as ourselves finding a good fit. We’ve seen some pretty interesting IoT use cases come our way, and hope to be able to share some examples in the near future.
Where to Learn More
We’ve only scratched the surface here, so for a deeper look into the complete landscape of the Internet of Things, check out the IoT webinar I hosted last week available for replay, as well as this in-depth whitepaper available for download. Of course, you can always reach out to us directly or get started with our services for free.
Legible? Absolutely. But it’s important to keep in mind that CTE’s are optimization fences. Optimizations like predicate pushdown are not currently available. More complicated queries may benefit from being rewritten with subqueries.
https://blog.2ndquadrant.com/postgresql-ctes-are-optimization-fences/
Good note! Worded another way (just to drive the point, for folks new to CTEs), using a CTE means you’re restricting what the query planner can do.
WITH queries are sleek, but not a silver bullet.