
Get a Job, Container: A Serverless Workflow with Iron.io
This post originally appeared on DZone
Overview
My previous post, Distinguished Microservices: It's in the Behavior, made a comparison between two types of microservices – real-time requests ("app-centric") and background processes ("job-centric"). As a follow-up, I wanted to take a deeper look at job-centric microservices as they set the stage for a new development paradigm — serverless computing.
Of course, this doesn't mean we're getting rid of the data center in any form or fashion — it simply means that we're entering a world where developers never have to think about provisioning or managing infrastructure resources to power workloads at any scale. This is done by decoupling backend jobs as independent microservices that run through an automated workflow when a predetermined event occurs. For the developer, it's a serverless experience.
Operational abstraction has been a key tenet of the cloud since day one, and the advancements across the entire stack have continued to provide developers with the ammo to ship applications more effectively. What sets this serverless pattern apart lies in the nature of the workloads. When we push an app to the cloud, we do so thinking about where it will live and how it will run. This is because it has a known IP address and open port to accept incoming requests. On the other hand, when we build a job, we do so only thinking about when it will execute. Even though there is compute involved, it's completely outside of the development lifecycle, thus making the paradigm "serverless".
In our history of operating a job processing platform at Iron.io, we've seen a wide range of production-grade use cases across our diverse customer base. Some common examples that fit this model well include:
- Data/File Processing: Heavy lifting workloads such as crunching a large data set, encoding a multimedia file, or filtering a stream of time series data points.
- Backend Transactions: Offloading individual user or device actions to the background such as processing a credit card or sending an email.
- ETL Pipelines: Data extraction, processing, and delivery of data such as analyzing machine data for an IoT system.
If we break this down, what we really have here is age-old programming techniques, modernized with cloud-native technologies, wrapped up with a bow through new architectural patterns. While many of the associated concepts have existed for some time, it's been the convergence of a few parallel evolutions to get the cloud ecosystem to where it is today:
- Microservices: Decoupling application components as individual services that perform a single responsibility enables workload independence and portability.
- Containers: Building, deploying, and running code within a lightweight, containerized runtime ensures consistency from development to production.
- Event-Driven: Breaking apart from the traditional request/response model allows for workflows that can react to dynamic environments automatically.
- DevOps: Automated resource provisioning, configuration, and management bring it all together at the infrastructure layer to abstract away everything but the API.
Table of Contents
Achieve Cloud Elasticity with Iron
Speak to us to find how you can achieve cloud elasticity with a serverless messaging queue and background task solution with free handheld support.
The Software Development Lifecycle
To be effective, these patterns require a new approach to the development process. At the forefront is container technologies such as Docker, which provide a myriad of benefits in terms of clarity and consistency. Iron.io was an early adopter of Docker and has since made it the primary method for working with the platform. To get started with Iron.io follow along with our Quick Start guide.
As a basic example, we'll take the simple task of sending an email using the Sendgrid API and package it up as an Iron.io job. By taking the input as a payload and requiring the API key as an environment variable, the job becomes portable enough to run through a serverless lifecycle independently.
Build: When the job is ready to build, specify the runtime by writing a Dockerfile that sets the executable, dependencies, and any additional configuration needed for the process. For this Ruby example, we will also include a Gemfile and run the bundler before building the Docker image to vendor the dependencies.
$ docker run --rm -v "$PWD":/worker -w /worker iron/ruby:dev bundle install --standalone --clean
$ docker build -t fortyfivan/sendemail:0.0.1 .
Upload: The Docker image from the build is then uploaded to a registry where it can be pulled on demand. This can be to a third party image repository such as Docker Hub, Quay.io, or a private registry. Once uploaded, the image is registered with an Iron.io project via the CLI.
$ docker push fortyfivan/sendemail:0.0.1
$ iron register fortyfivan/sendemail:0.0.1
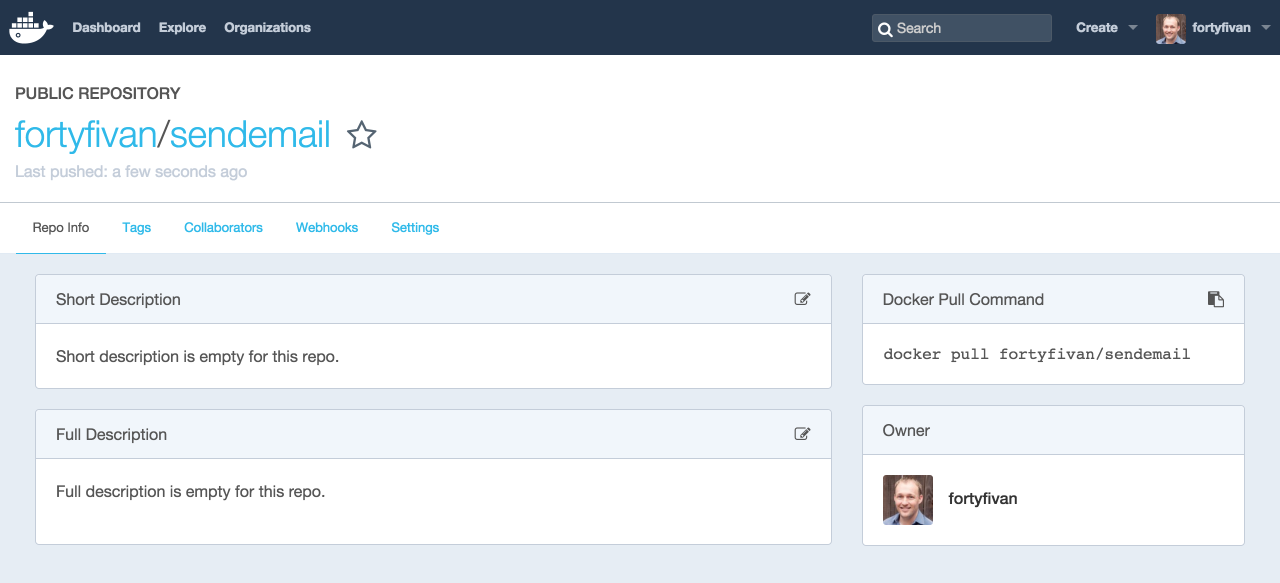
The image on Docker Hub
Set: Once the image is uploaded, you can set the triggers to determine when the job should execute. Events come in many forms — from an API request, on a system change, within code, from a webhook URL, on a schedule, or from a notification. For this example, we'll use the Iron.io API to schedule the job to run daily at 8AM.
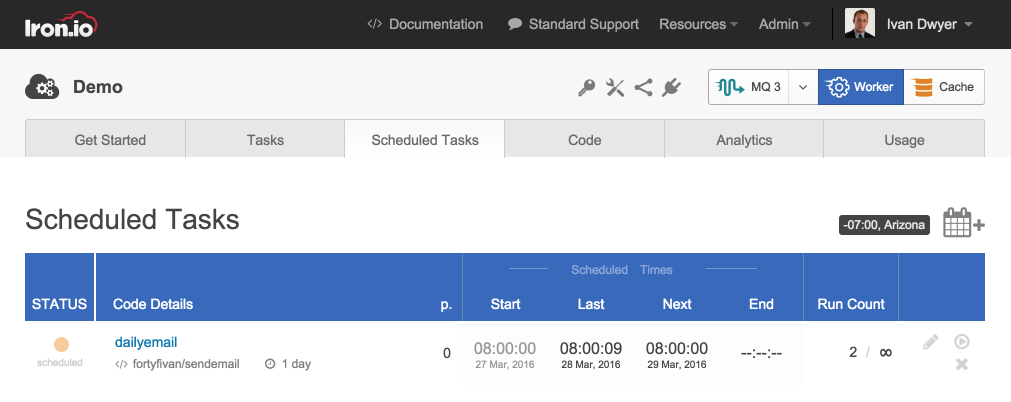
A Scheduled Job on Iron.io
Configure: Each job is an API endpoint in itself. It's important to configure the behavior so your jobs don't "go rogue". With Iron.io, you can properly set access controls, resource allocation, concurrency allowances, error handling, alerting, rate limiting, and more.
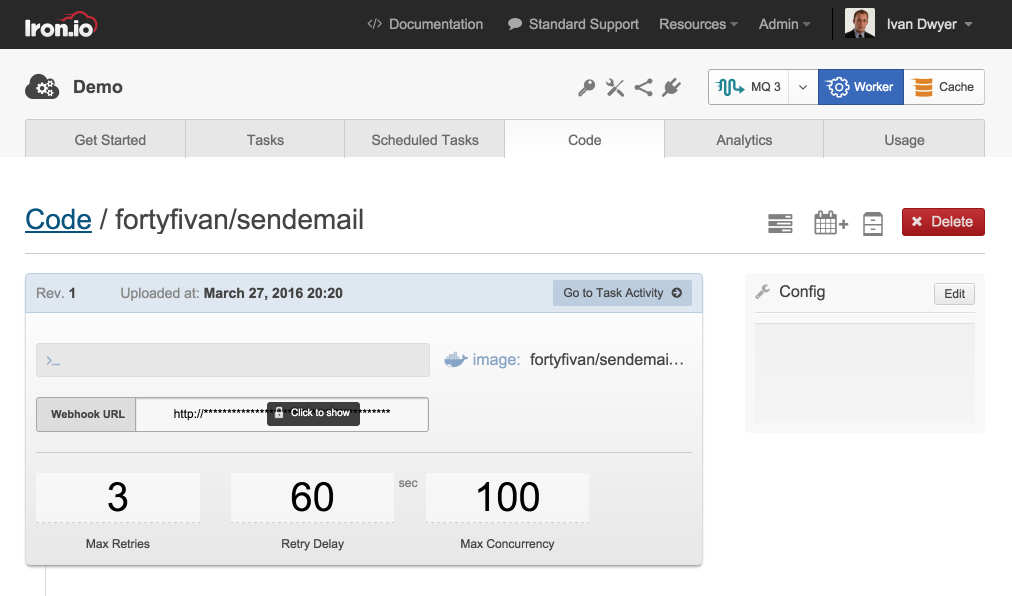
Job Configuration on Iron.io
Inspect: Background jobs can have a tendency to fall to the back of the mind (no pun intended). While the underlying system is maintenance-free, your code is still being executed, so you should have insight into its activity by monitoring status and performance in real-time and after the fact.
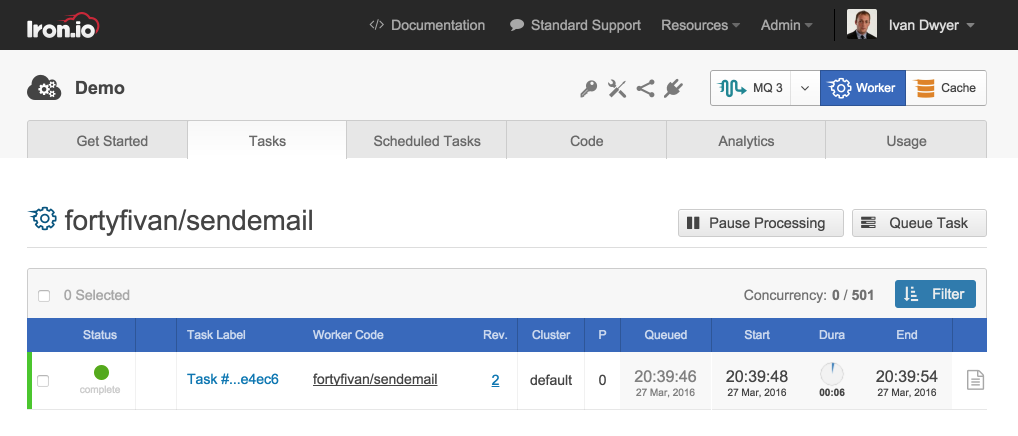
The Result of a Job on Iron.io
Iron.io Serverless Tools
Speak to us to learn how IronWorker and IronMQ are essential products for your application to become cloud elastic.
Operational Lifecycle
Even though the end-to-end operations are abstracted away from the developers, it's still worth knowing what's happening behind the scenes. When an event triggers an Iron.io job, the following process takes place:
- Queue Job: The job is posted to a message queue, which acts as the temporary store, holding the job in a persisted state until completed. The message includes the job metadata, runtime parameters, and any payload data to be passed into the job process itself.
- Get Job: Worker nodes are continually monitoring queues for jobs. When capacity is available, the worker pops a job off the queue and pulls the associated Docker image from its registry if a cached version of the image isn't already on the machine.
- Execute Process: The worker then runs the container with its given resource allocation. When the process is complete, the container is gracefully stopped and the resources are freed up for another job.
- Capture Results: The container's stdout/stderr logs are captured and delivered back to the system for dashboard display. If the process fails or timeouts, the job is placed back in the queue where it can be retried or canceled.
It’s Not Quite NoOps
What this trend truly represents is the continued importance of developer empowerment, so that businesses can keep pace with the ever-changing world around them. Serverless computing doesn't remove the need for infrastructure or operations, but it does keep it out of mind. Fire away.
Unlock the Cloud with Iron.io
Find out how IronWorker and IronMQ can help your application obtain the cloud with fanatical customer support, reliable performance, and competitive pricing.