
Using IronMQ for Delayed Processing and Increasing Scale (repost from Rackspace Blog)
Here’s a post of ours on using IronMQ to increase scale that recently appeared on the Rackspace Developers DevOps blog. Definitely worth checking out if you’re looking to scale out background processing and quicken the user response loop.

Using IronMQ for Delayed Processing and Increasing Scale
by Paddy Foran
 |
| Iron.io Guest Post |
It’s an established pattern to use message queues when building scalable, extensible, and resilient systems, but a lot of developers are still unsure how to go about actually implementing message queues in their architectures. Worse, the number of queuing solutions makes it hard for developers to get a grasp on exactly what a queue is, what it does, and what each solution brings to the table.
At Iron.io, we’re building IronMQ, a queuing solution we’ve developed specifically to meet the specific needs of today’s cloud architectures. In this post, we wanted to detail how to use queues in your applications and highlight a couple of unique capabilities that IronMQ provides (and which are not found in RabbitMQ and other non-native cloud queues).
One of the things that queuing does really, really well is getting work out of the way. Queues are built to be fast ways to make data available for other processes. That means that you can do more with your data, without making your customer wait. When it comes to response times every second matters, so only critical processing should take place within the immediate response loop. Queues let you do processing on data and perform non-immediate tasks without adding to your response time.
For the rest of the article, go here >>
Patterns, Code Samples, and a Demo Application
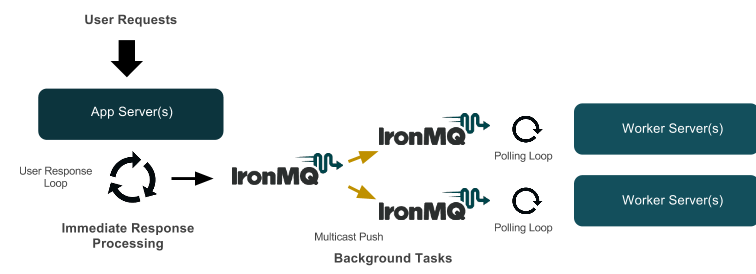 The post goes through several patterns for increasing scale by pushing tasks to the background and includes a number of code samples.
The post goes through several patterns for increasing scale by pushing tasks to the background and includes a number of code samples.
There’s also a demo application which includes basic model where workers are just polling a queue as well as more sophisticated patterns that push to multiple queues to handle different tasks (send an email, post to social media, create thumbnails, update user records, etc.)
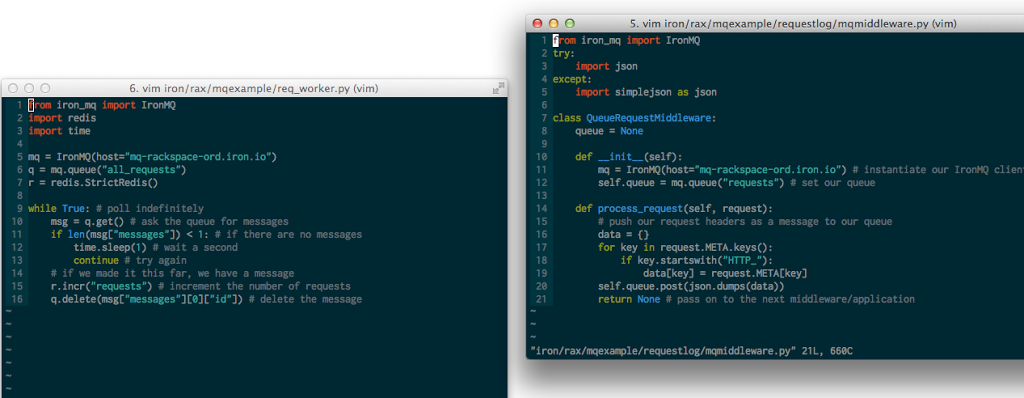
The code for the demo application can be found here on GitHub.