
1M msg/sec: IronMQv3 Hits Dos Commas
Table of Contents
ToggleOverview
IronMQ now has doors that go like this:

Nearly two years ago, we set out to build a more friendly message queueing service that still keeps up with the big boys. In previous posts we have only shown the performance of the single server version, but now it’s time to take the gloves off and showcase the production ready, clustered version of IronMQv3.
The de facto performance posts for distributed databases, message queues and the like are x can do a million/second y with z number of machines. I just wanted to do a million of something per second to compensate for always coming in last for the mile run in elementary school.
Lingering childhood issues aside…
Let’s skip straight to the graphs
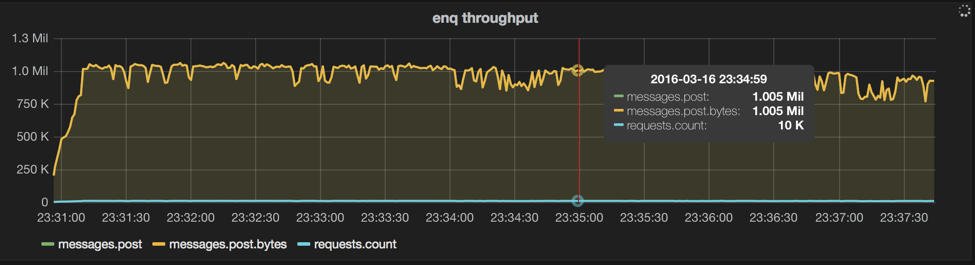
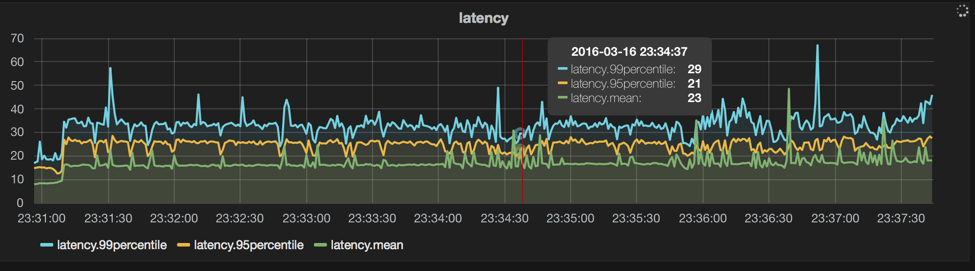
legend: body-size=1, n=100, machines=21, queues=7, threads=7, prods=12, cons=0
This is with no changes to the configuration or any special sauce compiled in, just out of the box MQ 3.2.17. The boxes used to accomplish this were 21 ec2 c3.4xl’s running MQ (using instance SSD w/ ext4), and 12 m3.medium’s running https://github.com/iron-io/monger (called prod/cons herein for producer/consumer), with 7 queues and 1 thread per queue per instance, for a total of 84 client threads (12 per queue), producing 100 1 byte messages at a time.
All tests herein use the same instance types and programs, we’ll change some of the other parameters slightly. All latencies are reported as they are seen from the client, in milliseconds.
Table of Contents:
- Normal Cluster Benchmarks
- Single Producer, 1byte message
- Single Producer, 1024 byte message
- Single Consumer, 1024 byte message
- Discoveries
Achieve Cloud Elasticity with Iron
Speak to us to find how you can achieve cloud elasticity with a serverless messaging queue and background task solution with free handheld support.
Normal cluster benchmarks
The test to get a million messages per second uses a relatively large MQ cluster -- 21 large ec2 instances -- where typically we run 3 or 5 node clusters of a smaller instance type. We wanted to spend some time -- the rest of the post -- illustrating the performance in a 3 node cluster to show more typical latencies as well as showing what single thread performance looks like.
As you will see below, the million per second case doesn’t have a much worse average latency than the single thread case -- and the million case used 83 more threads and 18 more MQs. This is because enqueueing messages is pretty easy to scale with respect to concurrency. We’re also able to keep the throughput and latency pretty stable, with just a few spikes. A queue ends up ultimately being bottlenecked on the performance of a single node (hence the multiple queues and nodes to get 1M/s) as we use a master-slave replication protocol, but we can scale across queues across machines -- and we automatically rebalance queues across all the nodes, unlike some queueing systems.
Single producer, 1-byte messages
Anyway, without further ado, here’s a 3 node cluster to help show single-threaded performance. These latencies are closer to what we observe on our production traffic (even with batches of 100), this test is the same as above, but with 3 nodes and only 1 queue, 1 thread, and 1 producer:
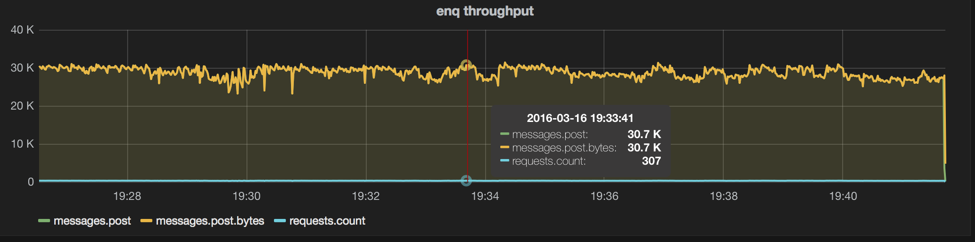
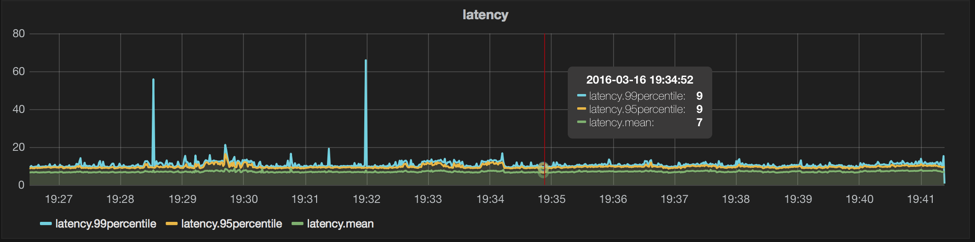
legend: body-size=1, n=100, machines=3, queues=1, threads=1, prods=1, cons=0
Single producer, 1024 byte messages
Message queueing systems tend to have better byte throughput numbers when not using 1-byte messages, as there are more relative bookkeeping and higher write amplification with smaller messages. Here’s a test the same as last (one producer), except with 1024 byte messages (still 100 at a time), you can see our byte throughput goes up, and our message throughput doesn’t suffer too much; messages are 1024x bigger, byte throughput increases over 600x, but message throughput only drops 40%. The byte throughput here is simply 1024 * number of messages/second, i.e. we don’t count the extra bytes of overhead that will be sent through the system. The ‘18.33 Mil’ below can be read as 18MB/s, so we’re doing a pretty steady 18MB/s with only the one thread. The bodies generated were random strings from /dev/urandom, which are not easily compressible; real-world message bodies are typically text-based and can lead to increases in byte throughput due to being easily compressed.
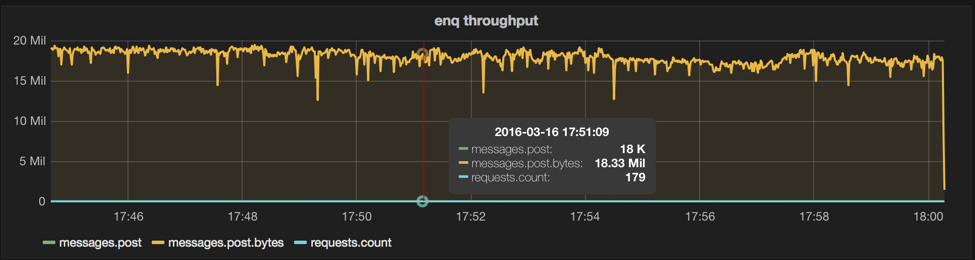
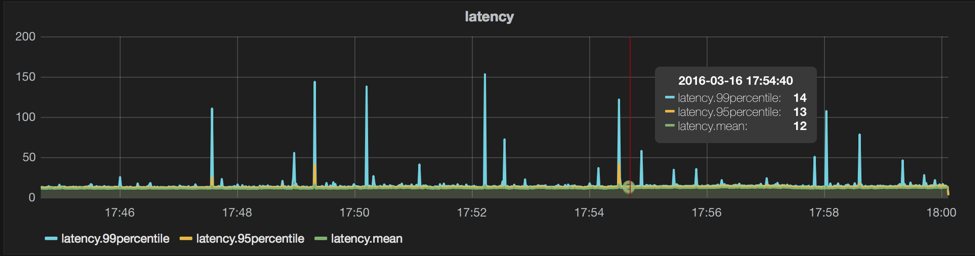
legend: body-size=1024, n=100, cons=0, machines=3, queues=1, threads=1, prods=1
Iron.io Serverless Tools
Speak to us to learn how IronWorker and IronMQ are essential products for your application to become cloud elastic.
Thanks for subscribing! Please check your email for further instructions.
Single consumer, 1024 byte messages
And, for symmetry, a graph with one consumer on 1 queue on 3 nodes w/ 1024 byte messages:
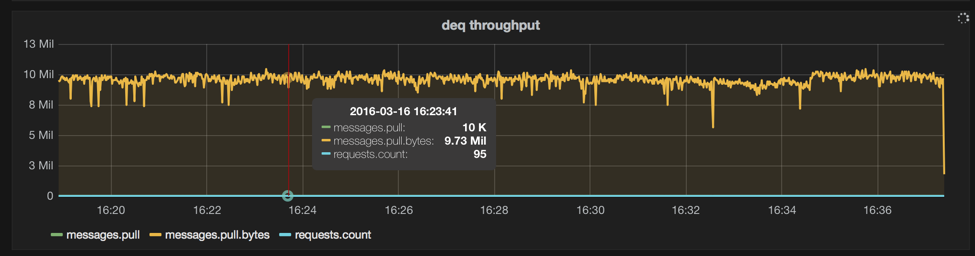

legend: body-size=1024, n=100, cons=1, machines=3, queues=1, threads=1, prods=0
The consumption rate of one thread is about half as fast as one producer thread. This is mostly from the higher latency variance displayed by dequeue because our underlying database is more optimized for writes than reads. It’s easy for users to add enough consumers to their queue in order to keep pace with their post rate in real-world usage.
However, dequeuing doesn’t scale as well across threads as enqueueing does so adding more threads doesn’t scale dequeue linearly. We hope to focus more on the scaling properties of different configurations and workloads in future posts. Note that the only work the consumers do is deleting (acking) the message, so there are twice as many requests against MQ in the consumer case than in the producing case (one to dequeue, one to delete). But enough charts, it’s time to tell war stories like we’re at the VA.
Discoveries
In the process of getting to this point, we ended up finding one particularly interesting bug, we’ll try to save the war story (sorry for getting your hopes up). Originally, our ID format would only allow 64k unique IDs to be generated per host per second. We had forgotten about this limitation after porting the ids from the old system and got some nasty new log lines. Until we figured out what it was, it looked like a ton of duplicate messages (which would be very bad). We had to update the ID format to now allow over a billion per second per host, which will never happen on a single host, especially since we’re persisting each message. No duplicate messages or duplicate IDs now. D’oh. There is an excellent blog post about IDs here, our new format is very similar.
Sometime in the near future...
Most of the tests only show what a single thread can do on a single queue, where typical use cases use tens to thousands of threads across multiple queues. All of the trials above also show only batches of 100, typically with relatively small messages; latency and request throughput look quite a bit better when only dealing in batches of 1 (at the cost of message throughput). From the million per second and various cases above we found a number of low-hanging fruit (looking at you, RPC, and our p99) and plan to address these before making the next post -- and now we have a sweet testing infrastructure to do so. In the next post we also hope to show results for different message sizes, consistency, batching, and different cluster configurations.
Want to know how it all works? The TL;DR is something similar to view stamped replication via 2PC and a gossip protocol for membership, with synchronous replication to all replicas; meaning that each message is consistent across all replicas. Our unit of sharding is queues, and we automatically spread them around onto different nodes. We use 3 replicas by default for queues, meaning in each of these tests, each message is written to 3 replicas before returning, and we serialize all reads and writes through one of the replicas for each particular queue (i.e. master-slave). At the bottom, we’re running embedded local rocksdb inside of each MQ process for persistent storage of queues and all metadata.
At present, we don’t have comprehensive documentation for all of the nitty-gritty, but we do enjoy chatting about this stuff if you want more details. Feel free to chat us up on the https://gophers.slack.com/messages gopher slack channel.
Want to give IronMQ a whirl for yourself? Recently, we made v3 the default for everyone, sign up and see what you think. Want to load test it or try running on your own machines? Send a note to our award-winning support team (I gave Ukiah one of my Little League trophies so we could say that).
about muah: Reed is currently programming computers at Iron.io. He spends most of his time trying to figure out why machines aren’t doing the things that he told them to do. He thinks this is enough of him talking about himself in third person.
Unlock the Cloud with Iron.io
Find out how IronWorker and IronMQ can help your application obtain the cloud with fanatical customer support, reliable performance, and competitive pricing.