
Docker in Production — What We’ve Learned Launching Over 300 Million Containers
 |
| Docker in Production at Iron.io |
Overview
Earlier this year, we made a decision to run every task on IronWorker inside its own Docker container. Since then, we've run over 300,000,000 programs inside of their own private Docker containers on cloud infrastructure.
Now that we’ve been in production for several months, we wanted to take the opportunity to share with the community some of the challenges we faced in running a Docker-based infrastructure, how we overcame them, and why it was worth it.
IronWorker is a task queue service that lets developers schedule and process jobs at scale without having to set up or manage any infrastructure. When we launched the service 3+ years ago, we were using a single LXC container to contain all the languages and code packages to run workers in. Docker allowed us to easily upgrade and manage a set of containers allowing us to offer our customers a much greater range of language environments and installed code packages.
We first started working with Docker v0.7.4 and so there have been some glitches along the way (not shutting down properly was a big one but has since been fixed). We’ve successively worked through almost all of them, though, and finding that Docker is not only meeting our needs but also surpassing our expectations. So much so that we’ve been increasing our use of Docker across our infrastructure. Given our experience to date, it just makes sense.
Table of Contents
Achieve Cloud Elasticity with Iron
Speak to us to find how you can achieve cloud elasticity with a serverless messaging queue and background task solution with free handheld support.
The Good
Here is a list of just a few of the benefits we’ve seen:
 |
| Large Numbers at Work |
Easy to Update and Maintain Images
Docker’s 'git' like approach is extremely powerful and makes it simple to manage a large variety of constantly evolving environments, and its image layering system allows us to have much finer granularity around the images while saving disk space. Now, we’re able to keep pace with rapidly updating languages, plus we’re able to offer specialty images like a new ffmpeg stack designed specifically for media processing. We’re up to 15 different stacks now and are expanding quickly.
Resource Allocation and Analysis
LXC-based containers are an operating system-level virtualization method that let containers share the same kernel, but such that each container can be constrained to use a defined amount of resources such as CPU, memory, and I/O. Docker provides these capabilities and more, including a REST API, environmental version control, pushing/pulling of images, and easier access to metric data. Also, Docker supports a more secure way to isolate data files using CoW filesystem. This means that all changes made to files within a task are stored separately and can be cleaned out with one command. LXC is not able to track such changes.
Easy Integration With Dockerfiles
We have teams located around the world. Being able to post a simple Dockerfile and rest easy, knowing that somebody else will be able to build the exact same image as you did when they wake up is a huge win for each of us and our sleep schedules. Having clean images also makes it much faster to deploy and test. Our iteration cycles are much faster and everybody on the team is much happier.
 |
| Custom Environments Powered by Docker |
A Growing Community
Docker is getting updates at an extremely fast rate (faster than Chrome even). Better yet, the amount of community involvement in adding new features and eliminating bugs is exploding. Whether it’s supporting images, supporting Docker itself, or even adding tooling around Docker, there are a wealth of smart people working on these problems so that we don’t have to. We’ve found the Docker community to be extremely positive and helpful and we’re happy to be a part of it.
Docker + CoreOS
We’re still tinkering here but the combination of Docker and CoreOS looks like it will have a solid future within our stack. Docker provides stable image management and containerization. CoreOS provides a stripped-down cloud OS and machine-level distributed orchestration and virtual state management. This combination translates into a more logical separation of concerns and a more streamlined infrastructure stack than presently available.
The Challenges
Every server-side technology takes fine-tuning and customization, especially when running at scale and Docker is no exception. (To give you some perspective, we run just under 50 million tasks and 500,000 compute hours a month and are rapidly updating the images we make available.)
Here are a few challenges we’ve come across in using Docker at heavy volume:
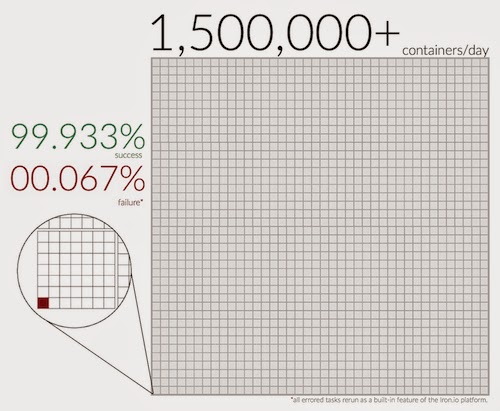 |
| Docker Errors – Limited and Recoverable |
Limited Backwards Compatibility
The quick pace of innovation in the space is certainly a benefit but it does have its downsides. One of these has been limited backward compatibility. In most cases, what we run into are primarily changes in command-line syntax and API methods and so it's not as critical an issue from a production standpoint.
In other cases, though, it has affected operational performance. By way of example, in the event of any Docker errors after launching containers, we'll parse STDERR and respond based on the type of error (by retrying a task, for example). Unfortunately, the output format for the errors has changed on occasion from version to version and so we've ended up having to debug on the fly as a result.
Issues here are relatively easy to get through but it does mean every update needs to be validated several times over and you’re still left open until you get it released into the land of large numbers. We should note that we started months back with v0.7.4 and recently updated our system to use v1.2.0 and so we have seen great progress in this area.
Limited Tools and Libraries
While Docker had a production-stable release 4 months ago, a lot of the tooling built around it is still unstable. Adopting most of the tools in the Docker ecosystem means adopting a fair amount of overhead as well. Somebody on your team is going to have to stay up to date and tinker with things fairly often in order to address new features and bug fixes. That said, we’re excited about some of the tools being built around Docker and can’t wait to see what wins out in a few of the battles (looking at you, orchestration). Of particular interest to us are etcd, fleet, and Kubernetes.
Triumphing Over Difficulty
To go in a bit more depth on our experiences, here are some of the issues we ran into and how we resolved them.
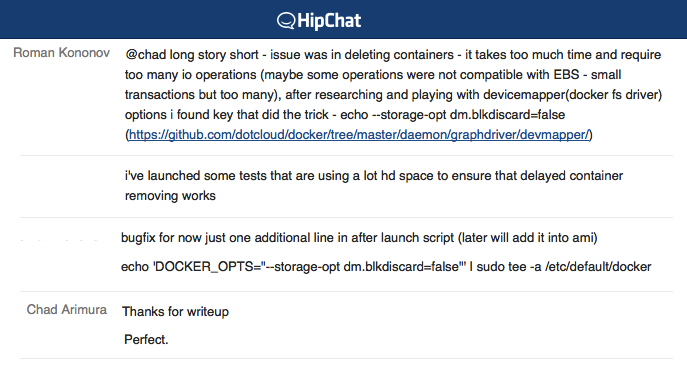 |
| An Excerpt from a Debugging Session |
This list comes mostly from Roman Kononov, our lead developer of IronWorker and Director of Engineering Operations, and Sam Ward who has also been instrumental in debugging and rationalizing our Docker operations.
We should note that when it comes to errors related to Docker or other system issues, we’re able to automatically re-process tasks without any impact on the user (retries are a built-in feature of the platform).
Long Deletion Times
 |
| The Fix For Faster Container Delete |
Deleting containers at the onset took way too long and required too many disk I/O operations. This caused significant slowdowns and bottlenecks in our systems. We were having to scale the number of cores available to a much higher number than we should have needed to.
After researching and playing with devicemapper (a docker filesystem driver), we found specifying an option that did the trick `--storage-opt dm.blkdiscard=false`. This option tells Docker to skip an expensive disk operation when containers are deleted, which greatly speeds up the container shutdown process. Once the delete script was modified, the problem went away.
Volumes Not Unmounting
Containers wouldn’t stop correctly because Docker was not unmounting volumes reliably. This caused containers to run forever, even after the task completed. The workaround was unmounting volumes and deleting folders explicitly using an elaborate set of custom scripts. Fortunately, this was in the early days when we were using docker v0.7.6. We removed this lengthy scripting once the unmount problem was fixed in docker v0.9.0.
 |
| Breakdown of Stack Usage |
Memory Limit Switch
One of the Docker releases suddenly added memory limit options and discarded the LXC options. As a result, some of the worker processes were hitting memory limits which then caused the entire box to become unresponsive. This caught us off guard because Docker was not failing even with unsupported options being used. The fix was simply to address – i.e. apply the memory limits within Docker – but the change caught us off guard.
Iron.io Serverless Tools
Speak to us to learn how IronWorker and IronMQ are essential products for your application to become cloud elastic.
Future Plans
As you can see, we’re pretty heavily invested in Docker and continue to get more invested in it every day. In addition to using it for containment for running user code within IronWorker, we’re in the process of using it for a number of other areas in our technical stack.
These areas include:
IronWorker Backend
In addition to using Docker for task containers, we’re in the process of using it to manage the processing that takes place within each server that manages and runs worker tasks. (The master task on each runner takes jobs from the queue, loads in the right docker environment, runs the job, monitors it, and then tear-down the environment after it runs.) The interesting thing here is that we’ll have containerized code managing other containers on the same machines. Putting all of our worker infrastructure environment within Docker containers also allows us to run them on CoreOS pretty easily.
IronWorker, IronMQ, and IronCache APIs
We’re no different from other ops teams in that nobody really likes doing deployments. And so we’re excited about wrapping all of our services in Docker containers for easy, deterministic environments for deployments. No more configuring servers. All we need are servers that can run Docker containers and, boom, our services are loaded. Should also note that we’re replacing our build servers – the servers that build our product releases for certain environments – with Docker containers. The gain here is greater agility and a simpler, more robust stack. Stay tuned.
Building and Loading Workers
We’re also experimenting with using Docker containers as a way to build and load workers into IronWorker. A big advantage here is that this provides a streamlined way for users to create task-specific workloads and workflows, upload them, and then run them in production at scale. Another win here is that users can test workers locally in the same environment as our production service.
Enterprise On-Prem Distribution
Using Docker as a primary distribution method our IronMQ Enterprise on-premises version simplifies our side of the distribution and provides a simple and universal method to deploy within almost any cloud environment. Much like the services we run on public clouds, all customers need are servers that can run Docker containers and they can get multi-server cloud services running in a test or production environment with relative ease.
From Production To Beyond
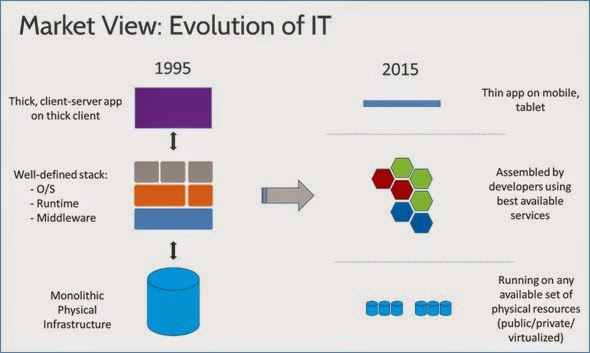 |
| The Evolution of IT (excerpted from docker.com) |
Docker has come a long way in the past year and a half since we saw Solomon Hykes launch it and give a demo on the same day at a GoSF meetup last year. With the release of v1.0, Docker is quite stable and has proven to be truly production-ready.
The growth of Docker has also been impressive to see. As you can see from the list above, we’re looking forward to future possibilities but we're also grateful that the backward view has been as smooth as it’s been.
Now only if we could get this orchestration thing resolved.
 |
| The Story Behind Our Use of Docker |
UPDATE:
For additional background on our use of Docker, take a look at the earlier post that we wrote called How Docker Helped Us Achieve the (Near) Impossible. In it, we discuss the decisions behind using Docker, the requirements we had going in, and more details on what it enables us to do.
For more insights on Docker as well as our emerging impressions of CoreOS, you can watch this space or sign up for our newsletter. Also, feel free to email us or ping us on twitter if you have any questions or want to share insights.
To try IronWorker for free, sign up for an account at Iron.io. We’ll even give you a trial of some of the advanced features so that you can see how processing at scale will change the way you view modern application development.
About the Authors

Travis Reeder is co-founder and CTO of Iron.io, heading up the architecture and engineering efforts. He is a systems architect and hands-on technologist with 15 years of experience developing high-traffic web applications including 5+ years building elastic services on virtual infrastructures. He is an expert in Go and is a leading speaker, writer, and proponent of the language. He is an organizer of GoSF (1450 members) and author of the following posts:
- How We Went from 30 Servers to 2: Go
- Go After 2 Years in Production
- How Docker Helped Us Achieve the (Near) Impossible

Roman Kononov is Director of Engineering Operations at Iron.io and has been a key part of integrating Docker into the Iron.io technology stack. He has been with Iron.io since the beginning and has built and contributed to every bit of Iron.io’s infrastructure and operations framework. He lives in Kyrgyzstan and operates Iron.io’s remote operations team.
Additional Contributors – Reed Allman, Sam Ward
About Iron.io
Iron.io is the maker of IronMQ, an industrial-strength message queue, and IronWorker, a high-concurrency task processing/worker service. Every production system uses queues and worker systems to connect systems, power background processing, process transactions, and scale out workloads. Iron.io's products are easy to use and highly available and are essential components for building distributed applications and operating at scale. Learn more at Iron.io.
About Docker
Docker is an open platform for distributed applications for developers and sysadmins. Learn more at docker.com.
Unlock the Cloud with Iron.io
Find out how IronWorker and IronMQ can help your application obtain the cloud with fanatical customer support, reliable performance, and competitive pricing.