
How to Build an ETL Pipeline for ElasticSearch Using Segment and Iron.io
Overview
ETL is a common pattern in the big data world for collecting and consolidating data for storage and/or analysis. Here's the basic process:
- Extract data from a variety of sources
- Transform data through a set of custom processes
- Load data to external databases or data warehouses
 |
| Segment + Iron.io + Elasticsearch = A Modern ETL Platform |
While it may seem unnecessary to follow this many steps as the tools around Hadoop continue to evolve, forming a cohesive pipeline is still the most reliable way to handle the sheer volume of data.
The extract process deals with the different systems and formats, the transform process allows you to break up the work and run tasks in parallel, and the load process ensures delivery is successful. Given the challenges and potential points of failure that could happen in any one of these steps, trying to shorten the effort and consolidate it into one process or toolkit can lead to a big data mess.
IronMQ + IronWorker
This ETL pattern is a common use case with many of our customers, who will first use IronMQ to reliably extract data from a variety of sources, and then use IronWorker to perform custom data transformations in parallel before loading the events to other locations. This combination of IronMQ and IronWorker not only makes the process straightforward to configure and transparent to operate, but it also moves the whole pipeline to the background so as not to interfere with any user-facing systems.
Leveraging the scaling power of Iron.io allows you to break up the data and tasks into manageable chunks, cutting down the overall time and resource allocation. Here’s one example of how HotelTonight uses Iron.io to populate AWS’s RedShift system to give them real-time access to critical information.
In this post, we thought we'd walk through a use case pattern that provides a real-world solution for many – creating a customized pipeline from Segment to ElasticSearch using Iron.io.
Table of Contents
Achieve Cloud Elasticity with Iron
Speak to us to find how you can achieve cloud elasticity with a serverless messaging queue and background task solution with free handheld support.
Segment and Iron.io: An Integration That Does Much More
With the growing number of tools available to developers and marketers alike for monitoring, analytics, testing, and more, Segment is quickly becoming a force in the industry, serving as the unifying gateway for web-based tracking applications. In fact, Segment has become one of our favorite internal tools here at Iron.io thanks to its ability to consolidate the delivery to various APIs with just one script. Whether it's Google Analytics, Salesforce, AdRoll, or Mixpanel just to name a few, Segment eliminates the pain of keeping all of our tracking scripts and tags in order within our website, docs, and customer dashboard for the monitoring user activity. How nice.
We're not alone in our appreciation of Segment, and we've included an IronMQ integration of our own that you can read about here. Our integration follows a unique pattern in that it's not just a single point connect, though. Instead, connecting IronMQ to Segment as an endpoint creates a reliable data stream that can then be used for a wide range of use cases. The benefits of doing so include:
- Data buffering – IronMQ provides a systematic buffer in the case that endpoints may not be able to handle the loads that Segment may stream.
- Data resiliency – IronMQ is persistent with FIFO and one-time delivery guarantees, ensuring that data will never be lost.
- Data processing – Adding IronWorker to the end of the queue can provide you with scalable real-time event processing capabilities.
A Data Pipeline into ElasticSearch
ElasticSearch is an open-source, distributed, real-time search and analytics engine. It provides you with the ability to easily move beyond simple full-text search to performing sophisticated data access, collection, indexing, and filtering operations. ElasticSearch is being used by some of the largest businesses in the world and is growing at a rapid pace. You can read about the many customer use cases with ElasticSearch here.
The segment itself does a great job of collecting data and sending it to individual services. Many users, however, will want to perform additional processing on the data before delivering it to a unified database or data warehouse such as ElasticSearch. Some example uses could be for building out customer dashboards or internal analytics tools. With ElasticSearch at the core, you can translate events into actionable data about your customer base. Business intelligence in today's environment is driven by real-time searchable data, and the more you can collect and translate, the better.
Iron.io Serverless Tools
Speak to us to learn how IronWorker and IronMQ are essential products for your application to become cloud elastic.
ETL Pipeline Instructions: Step-By-Step
The following tutorial assumes that you've installed Segment into your website. From here we'll walk through switching on the IronMQ integration and then running IronWorker to transform the data before loading it into ElasticSearch.
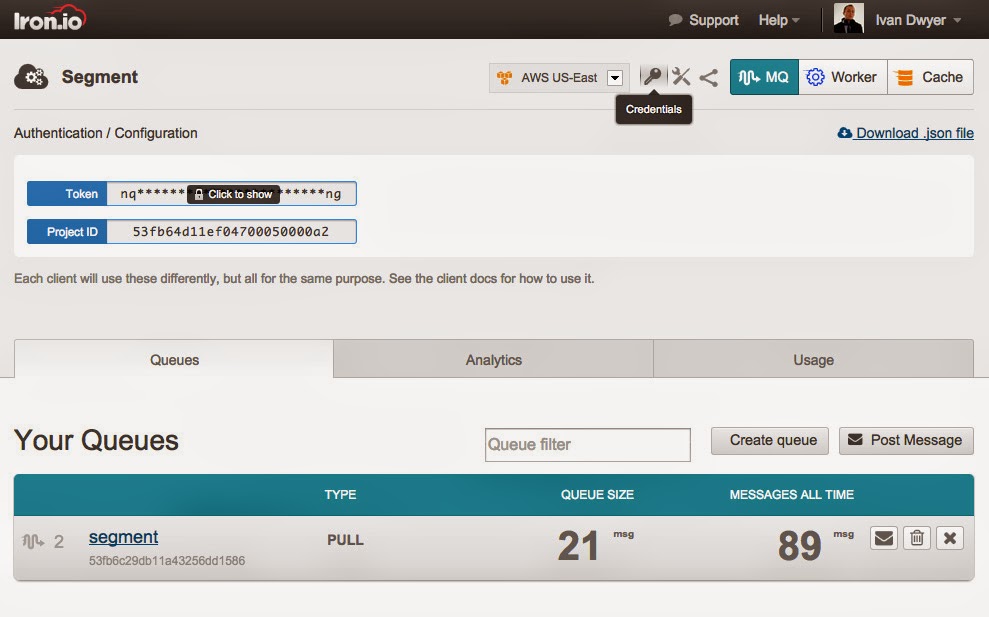 |
| Copy your Iron.io Credentials from the Dashboard |
1. Connecting IronMQ to Segment
With Segment and Iron.io, building a reliable ETL pipeline into ElasticSearch is simple. The initial extract process, often the origin of many headaches, is already handled for you by piping the data from Segment to IronMQ.
Flipping on the IronMQ integration within the Segment dashboard automatically sends all of your Segment data to a queue named "segment". All you need to do to initiate the process is create a project within the Iron.io HUD and enter the credentials within Segment.
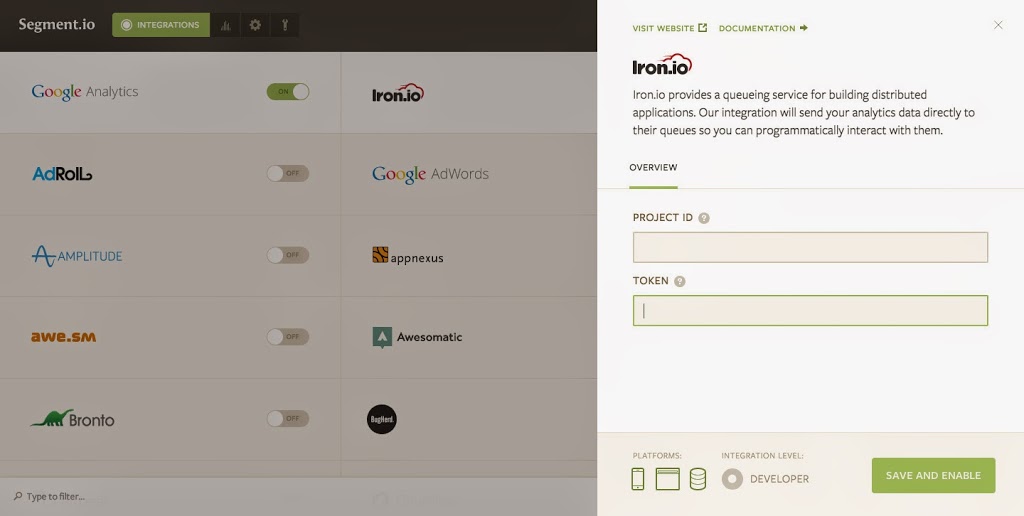 |
| Enter Your Iron.io Credentials into Segment |
2. Transforming the Data
Now that we have our Segment data automatically sending to IronMQ, it's time to transform it prior to loading it into ElasticSearch.
Let's say we want to filter out identified users based on their plan type so only paid user data gets sent to ElasticSearch. In the case of building customer dashboards, this allows us to maintain a collection of purely usable data, making our indexing and searching more efficient for the eventual end use case.
We're going to create a worker to pull messages from the queue in batches, filter the data, and then load into an ElasticSearch instance. For simplicity's sake, we're going to create a Heroku app with the Bonsai add-on, a hosted ElasticSearch service. Leveraging IronWorker's scheduling capabilities, we can check for messages on the queue at regular intervals.
With IronMQ and IronWorker, we can also ensure that we're not losing any data in this process and that we're not overloading our ElasticSearch cluster with too much incoming data. Buffering and, buffering and...
Segment Data
Before we get to our worker, let's examine the data from the Segment that gets sent to the queue. The segment is vendor agnostic, making it very simple to interact with the exported data. The Tracking API that we'll be working with consists of several methods: identify track, page, screen, group, and alias. You can dive into the docs here. We use the Ruby client within the Iron.io website to see where our users are going. Any page we want to track, we just place this line on the Controller.
Analytics.track( user_id: cookies[:identity], event: "Viewed Jobs Page" )
Here is a typical basic identify record in JSON format... parsed, filtered, and prettied. This is plenty enough for us to make our transformation before loading into ElasticSearch.
{
“action” : “Identify”,
“user_id” : “123”,
“traits” : {
“email” : “ivan@iron.io”,
“name” : “Ivan Dwyer”,
“account_type” : “paid”
“plan” : “Enterprise”,
},
“timestamp” : “2014-09-10-02T00:30:00.276Z”
}
Worker Setup
Now let's look at creating the task that performs the business logic for the transformation. With IronWorker, you create task-specific code within a "worker" and upload it to our environment for highly scalable background processing. Note that this example uses Ruby, but IronWorker has support for almost every common language including PHP, Python, Java, Node.js, Go, .NET, and more.
For this worker, the code dependencies will be the irommq, elasticsearch, and JSON gems. It’s a quick step to create the .worker file that contains the worker config and we'll put the Bonsai credentials in a config.yml file.
Our worker in this example will be very simple as a reference point. With the flexible capabilities of IronWorker, you are free to build out any transformations you'd like and load them to any external service you prefer. The Segment queue can grow rapidly (because of traffic), so we'll want to schedule this worker to run every hour and clear the queue each time. If your queue growth gets out of hand, you can create a master worker that splits up the processing to slave workers that can run concurrently, significantly cutting down the total processing time. Just another reason keeping the ETL process within Iron.io is the way to go.
Once we initiate both the IronMQ and ElasticSearch clients, we can make our connections and start working through the queue data before loading to Bonsai. We know from our Segment integration that the queue is named "segment", and that our paid users are tagged with an "account_type" trait. This allows us to easily loop through all the messages and check whether or not each record meets our requirements. Post the data to Bonsai and then delete the message from the queue. Pretty simple.
3. Upload and Schedule our Worker
Now we can use the IronWorker CLI tool to upload our code package.
$ iron_worker upload segment
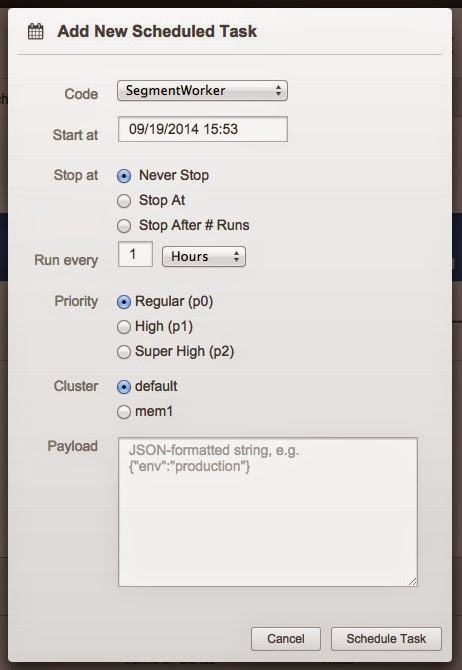 |
| Add a New Scheduled Task |
Once the code package is uploaded and built, we can go to the HUD and schedule it to run. Select the "SegmentWorker" code package and set the timing. Every hour at regular priority seems fine for this task as this is a background job with no time sensitivity. What's that mem1 cluster you ask? Why that’s our new high memory worker environment meant for heavy processing needs.
Now our worker is scheduled to run every hour with the first one being queued up right away. We can watch its progress in the Tasks view.
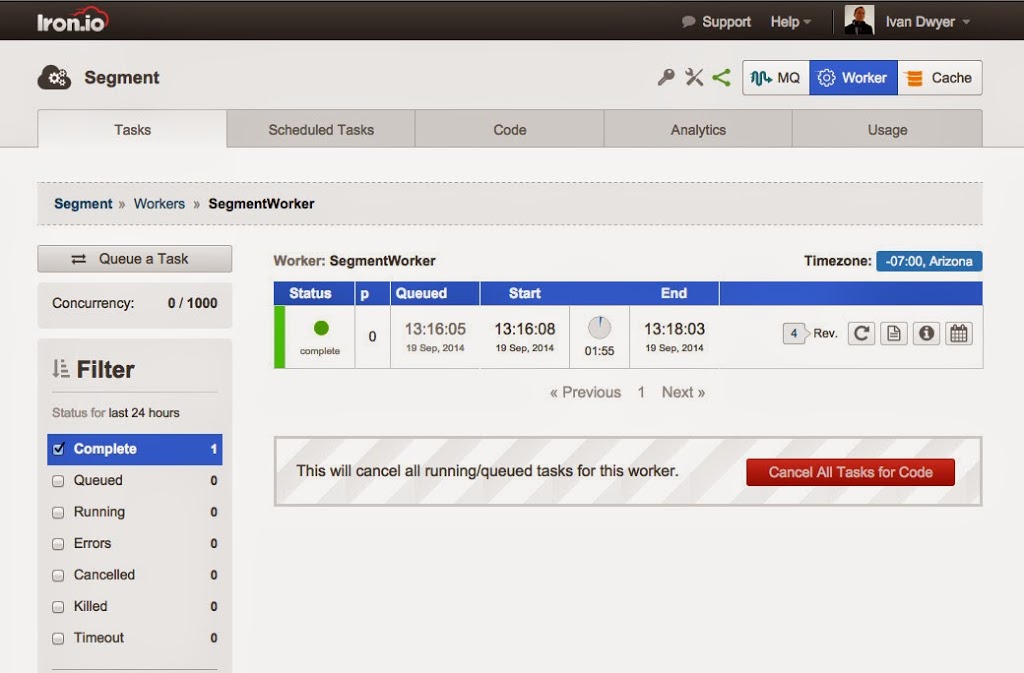 |
| View Task Status in Realtime |
Once it's complete, we can check the task log to see our output. Looks like our posting to ElasticSearch was successful.
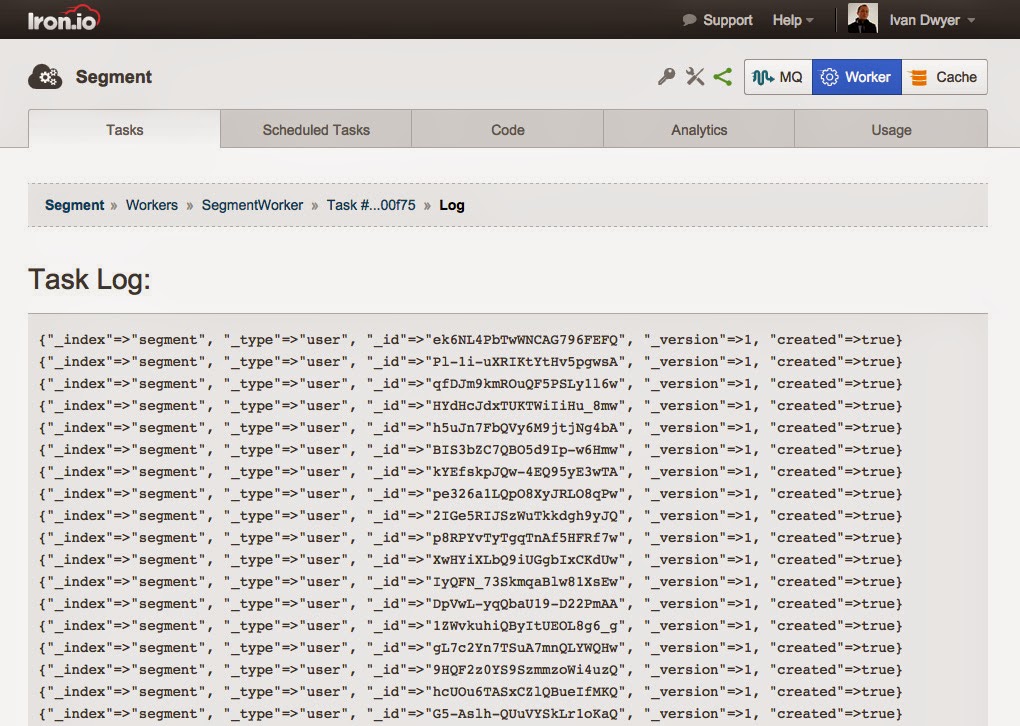 |
| Detailed log output |
Just to be sure, let's check our Bonsai add-on in Heroku. Looks like we successfully created an index and populated it with documents. Now we can do what we like within ElasticSearch.
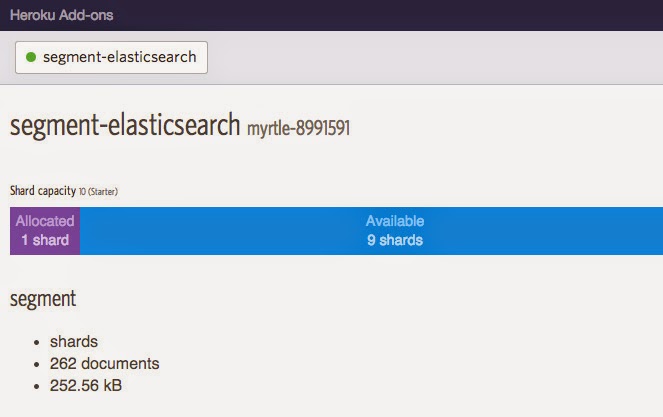 |
|
|
There you have it. With the Iron.io integration on Segment, you can build your own ETL pipeline any way you'd like.
Get Running in Minutes
To use Iron.io for your own ETL pipeline, signup for a free account (along with a trial of advanced features).
Once you have an Iron.io account, head over to Segment and flip the switch to start sending your data to IronMQ.
With the Segment and Iron.io integration in place, you can branch the data to other locations as well as tie in IronWorker to transform the data. Let us know what you come up with... we'll write about it and send t-shirts your way!
Unlock the Cloud with Iron.io
Find out how IronWorker and IronMQ can help your application obtain the cloud with fanatical customer support, reliable performance, and competitive pricing.