
How We Went from 30 Servers to 2: Go

When we built the first version of IronWorker, about 3 years ago, it was written in Ruby and the API was built on Rails. It didn’t take long for us to start getting some pretty heavy load and we quickly reached the limits of our Ruby setup. Long story short, we switched to Go. For the long story, keep reading, here's how things went down.
Table of Contents
The Original Setup
First, a little background: we built the first version of IronWorker, originally called SimpleWorker (clever name right?), with Ruby. We were a consulting company building apps for other companies and there were two really hot things at that time: Amazon Web Services and Ruby on Rails. So we built apps using Ruby on Rails on AWS and we got some great clients. The reason we built IronWorker was to scratch our own itch. We had several clients building hardware devices that constantly sent in data, 24/7, and we had to collect it and process it into something useful. Typically scheduling big jobs to run through the data every hour, then every day, and so on. We decided to build something we could use for all our clients without having to manage a bunch of infrastructure for each of them to process this data. So we built "workers as a service" that we used internally for a while, then we thought there must be other people that need this so we decided to make it public and thus IronWorker was born.
Our sustained CPU usage on our servers was approximately 50-60%. When it increased a bit, we’d add more servers to keep it around 50%. This was fine as long as we didn’t mind paying for a lot of servers (we did mind). The bigger problem was dealing with big traffic spikes. When a big spike in traffic came in, it created a domino effect that would take down our entire cluster. At some threshold above 50%, our Rails servers would spike up to 100% CPU usage and become unresponsive. This would in turn cause the load balancer to think it failed and take it out of the pool, thereby applying the load that the unresponsive server would have been handling to the remaining servers. And since the remaining servers are now handling the load of the lost server plus the spike, inevitably a second server would go down, the load balancer would take it out of the pool and so on. Pretty soon every server in the pool is toast. This phenomenon is otherwise known as a colossal clusterf**k (ref: +Blake Mizerany).
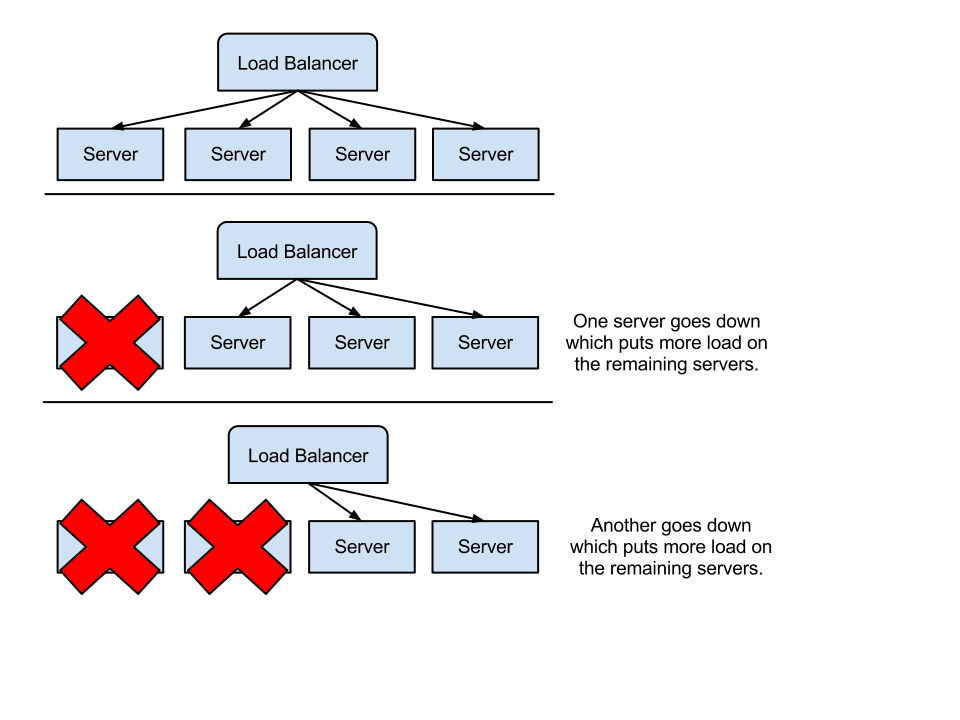 |
| Here's a simple drawing of the domino failure effect. |
The only way to avoid this with the setup we had was to have a ton of extra capacity to keep our server utilization much lower than what it was, but that meant spending a ton of money. Something had to change.
We Rewrote It
We decided to rewrite the API. This was an easy decision, clearly, our Ruby on Rails API wasn't going to scale well, and coming from many years of Java development and having written a bunch of things that handled tons of load with way fewer resources than what this Ruby on Rails setup could handle, I knew we could do a lot better. So then the decision came down to which language to use.
Iron.io Serverless Tools
Speak to us to learn how IronWorker and IronMQ are essential products for your application to go serverless.
Choosing a Language
I was open to new ideas since the last thing I wanted to do was go back to Java. Java is (was?) a great language in a lot of ways such as performance, but after writing Ruby code for a few years, I was hooked on how productive I could be. Ruby is fun, plain and simple.
We looked at other scripting languages with better performance than Ruby (which wasn't hard) like Python and JavaScript/Node, we looked at Java derivatives like Scala and Clojure, and other languages like Erlang (which apparently AWS uses) and Go (golang). Go won. The fact that concurrency was such a fundamental part of the language was huge; the standard core library had almost everything we needed to build an API service; it's terse; it compiles fast; like Ruby, Go is fun; and finally, the numbers don't lie. After some prototyping and performance testing, we knew we could push some serious load through it. With some convincing of the team ("It's all good, Google is backing it"), we bit the bullet.
When we first decided on Go, it was a risky decision. There wasn't a big community, there wasn't a lot of open source projects, there weren't many (if any) success stories of production usage. We also weren't sure if we would be able hire top talent if we chose Go, but we soon found out that we could get top talent because we chose Go. We were one of the first companies to publicly say that we were using it in production and the first company to post a Go job to the golang mailing list. Top-tier developers wanted to work for us just so they could use Go in their day-to-day lives.
After Go

After we rolled out our Go version, we reduced our server count to two and we really only had two for redundancy. They were barely utilized, it was almost as if nothing was running on them. Our CPU utilization was less than 5% and the entire process started up with only a few hundred KB's of memory (on startup) vs our Rails apps which were ~50MB (on startup). Compare that even to JVM memory usage! It was night and day. And we've never had another colossal clusterf**k since.
We have grown a lot since those early days. We now get way more traffic, we added two more services (IronMQ and IronCache), and we run 100's of servers to handle our customer's needs. And it's all powered by Go on the backend. In retrospect, it was a great decision to choose Go as it's allowed us to build great products, to grow and scale, and attract grade A talent. And I believe it will continue to help us grow for the foreseeable future.
UPDATE: Lots of conversation about this article at Hacker News.
 UPDATE: We posted another article on our experiences with Go called Go After 2 Years in Production. In it, we address issues of performance, memory, concurrency, reliability, deployment, and talent acquisition. As with above, this article also generated a large thread of comments at Hacker News.
UPDATE: We posted another article on our experiences with Go called Go After 2 Years in Production. In it, we address issues of performance, memory, concurrency, reliability, deployment, and talent acquisition. As with above, this article also generated a large thread of comments at Hacker News.
Take Off With Iron.io
Find out how IronWorker and IronMQ can help your application get up and running with fanatical customer support, reliable performance, and competitive pricing.
74 Comments
Leave a Comment
You must be logged in to post a comment.
I’d be interested to hear of any drawbacks you encountered on your journey. From a performance side it’s a huge win. Any sticking points as you built or deployed the new Go version?
There were no major drawbacks I can think of offhand, other than learning a new language. Some minor drawbacks were limited community libraries, but there were libs for the most important (and hard) things like db drivers so that wasn’t so bad.
Regarding deployment, there couldn’t be anything easier. Go compiles into a single static binary so deploying it is a piece of cake.
The only thing required then is that the build server and deployment target server are the same?
Go can be cross-compiled to at least Windows, Mac, and Linux, so not even that is necessarily a requirement.
That’s right, but even that’s not 100% true since apparently you can compile into different architectures. https://goo.gl/E1f7g
Can you push changes live to the production environment? Or do you have to recompile, take the server down, and start it up again?
We always have multiple servers so we do rolling deploys, zero downtime. Not really related to the language though.
i’m also writing proxies and automation in Go and loving it. easy and fun. fun is important!
is there any third party component that was not support on Go such as database library or similar that needed some extra work from your side ?
Fortunately, like I said above, there were database drivers already so the most important things were covered.
Do you regret using Ruby for the first implementation?
Do you recommend to start a business from scratch with something volatile and new like Go?
I still see huge benefits starting with Ruby and Rails, specially when using a BDD approach and “lean”/agile product cycles. When I checked other options recently, there was no other option that provided such a productive way with such a high quality.
I don’t regret it, but it would have been wise to have written it with something better, especially considering what we were building. I don’t think we really thought it would grow so quickly though. If I were to build another API based service where you would expect to get a lot of traffic, I’d start with something like Go.
UI’s and what not don’t get as much traffic (in general) so Rails is probably better for that since you’ll be a lot more productive.
Rails is not and have never been a good fit for APIs. try sinatra or just plain rack.
Although Go is fairly general-purpose, I think this is exactly the type of thing it is good for. I’m sure Google’s own use of Go is similar to this.
What would you say was the impact of knowing the business already when rewriting?
Was your acquired knowledge of the problem and the solution also responsible for this performance increase?
What do you use for request handling? Anything more convenient then builtin http.Handler?
We use gorilla toolkit for routing: https://www.gorillatoolkit.org
Thanks for the write up, great post and very helpful. We write a lot of Ruby and Ruby on Rails applications. I have been considering something more performant and have been considering C++ v11 but Go is on the radar.
Can you suggest resources and guidance for writing API’s in Go?
Check out
the wiki: https://code.google.com/p/go-wiki/w/list
the blog: https://blog.golang.org/
the mailing list: https://groups.google.com/forum/?fromgroups#!forum/golang-nuts
especially the references of existing projects: https://code.google.com/p/go-wiki/wiki/Projects
“We decided to rewrite the API. This was an easy decision, clearly our Ruby on Rails API wasn’t going to scale well […]”.
Did you rewrite your Service of the Interface that exposes it to users?
Does your entire Service consist of only the (Application Programming) Interface?
Why is every Service referred to as an API in the app/startup/webscale/disruptive/cloud community?
I suspect that you did not spend time thinking about how to reduce your server load and blamed Ruby prematurely. I have had my hands on many Rails code bases and deployments and I can tell you that rookie mistakes are common even in work done by high-profile dev shops. Database indexes missed, no understanding of unix processes and server management, dumb algorithms, failing to use active record or other parts of rails properly, prematurely factoring a system into a bunch of arbitrary “services” that talk to each other and make everything slow… these are just some of the things I have seen. A lot of Java guys carry bad habits into Ruby land. Also I think people are way over-using expensive cloud services when a simple colo’d Mac Mini server or 3 with SSDs handle the same traffic far more inexpensively than a boatload of VPS or AWS instances.
I understand wanting to try something different but I suspect your heart was not in it and you wanted to use this as an excuse to implement in a new platform/language via rewrite. Rewrites are always fun and I think they are a great way to learn a new platform or language. Go sounds neat. I’ll check it out.
I suspect that this article is making more out of switching to Go and less out of switching from Ruby, the latter likely more significant.
It’s all about the right tool for the job. Go is designed for building infrastructure like messages queues, Rails is for building apps like Basecamp.
Have you folks considered JRuby as an option?
Could you give more infomation on what make you choose go against the other alternatives?
I already tried clojure/scale, racket, node and a bit of golang. I’m still not sure between go or node to replace our python api.
There are many reasons we chose Go: it’s fast, right up there with c++ and Java; it’s a nice language to write in, very terse; compiles fast, starts fast; the core libraries are very well done and cover most things people need in today’s world; it’s concurrency support is great for building API’s; etc.
I personally wouldn’t touch node with a ten foot pole, mostly because I can’t stand Javascript. But some people seem to like it and have gotten good performance out of it so if you like Javascript (which I’ll never understand), then it could be a good option.
coming from a C/C++ background i was confused by the go syntax and could never be comfortable. i was expecting a smooth transition to go syntax wise. Then i looked at D and it was good infact really good especially for those from C++. the only thing missing from D is a distributed programming toolkit i hope folks are already thinking about it and will only be a matter of few years. I am betting on D over Go.
FWIW D and Rust never got off the ground. Go is actually going mainstream already. Consider that.
Rust is not even at version 1.0, give it a chance.
It does take a bit to wrap your head around Go’s syntax, but once you do, it all becomes second nature, just like any language.
Did you select Go or reject the other alternatives? I would especially like to hear why Scala (which has very good support for concurrency) was not picked.
The problem with Scala, for my taste, it’s the Java luggage.
Scala runs on a JVM and that is good for some things (you can use a lot of existing libraries) and bad for others, like memory usage (huge, specially in 64bit systems), the fact that Scala strings are Java Strings makes them more storage inefficient than UTF-8 based Go strings…
And this things get inherited even when you don’t notice.
For instance, both Scala and Go use a flavour of the CSP model for concurrency and both are “function based”, while Java is “Class based”, that is the minimum unit of code is the function while in Java you have to create a whole class for anything, even to call a single method (=un-asked-for bureaucracy, if you will)
But Scala, maybe due to its inheritance, uses Actors, while Go uses goroutines and channels. Having Actors for concurrency, that is a class with “a channel sticked to it”, is like having a class with a method just to call a function:
– Sometimes you just need a task to do something, and you don’t care of its results, why would you have the channel created then?
– Sometimes you need to have a task listen various channels at once, that is not the out of the box actor pattern…
– Sometimes you need to have several tasks listen the same channel…
In my opinion, Go’s goroutines and channels are a better abstraction, easier to understand and more flexible at the same time.
josvazg nailed it, “Java luggage”. I would have used baggage, but hey. 😉 I wrote Java programs for a loooong time and i know how powerful it can be. Java itself has great concurrency support, not just Scala so I definitely took that into account. Go routines and channels are just a much nicer, cleaner way of doing things. And go-routines are very lightweight compared to Java’s threading.
(Ups! English is not my first language, as it’s probably already obvious. I thought luggage and baggage where kind of synonyms… I meant the “legacy” in general)
Go routines light weight internal design is so cool that Java and other JVM-based languages like Scala should consider pushing to “backpor” support for them in the runtime. Because you cannot copy them as a library, as you can do with channels, for instance.
Java strings being UTF-16 by default is also a big penalty to pay for JVM compliance. Lets just admit that Rob Pike, co-inventor of both UTF-8 and Go, was right and Java’s decision on 16bit chars or C/C++ wide-chars where just plain wrong. Most of the time, a character is 1byte, so it does not make sense to use more than 1byte of storage. And when the character is more than a byte, it can be more than 2bytes and also normally carries more information, for instance, Chinese characters are 2 or 3 bytes long, but they also “carry” more information and, if I am not mistaken, are mapped to 2-3 latin characters anyway making full syllable.
josvazg: luggage and baggage are nearly synonyms when referring to something you carry to the airport. When referring to a problematic legacy, baggage is the preferred term 🙂
Great article. I wish it had any technical information. +1 for Go with anecdotal evidence. 🙂
Perhaps I’ll have to do a follow up and go into more detail on the technical side of things.
that!
Just curious, you said you looked into alternatives like Java, JavaScript/NodeJS. What made you decide against using NodeJS ?
Javascript.
Good article, however I also would like to know why you did not choose to build your new API using NodeJs.
Good article, however I also would like to know why you did not choose to build your new API using NodeJs.
So, you haven’t considered Perl?
We were about to choose Perl… but then someone slapped me upside the head. 😉
Great retrospective, thanks for sharing!
Other fellows already asked similar questions, but as someone who’s evaluating languages with better concurrency models, I’m curious about why not Clojure? I drew some conclusions from your response for Scala, but (still) I don’t know enough of Scala to do a side-by-side comparative. Thanks!!
Will be great if you can throw some light on “where” and in “what kind of work load” Ruby did not do well? I wonder why Ruby had hogged CPU? As I understand there are 4 kinds of workloads in your system (please correct me if I am wrong)
1. Handling several concurrent client connections.
* How many concurrent clients are we talking about here?
* Use of blocking sockets will require a separate thread for each connected client? Was Ruby not able to support many threads?
* Non-Blocking sockets will require lesser number of threads. Note: I am from a Java background and Java’s NIO scales well in handling volumes of concurrent sockets)
2. Handling volumes of data. (Data mining/aggregation) This is an IO/CPU intensive work load.
* I dont think you would had done data-processing in ruby. Please correct me if I am wrong.
* Scaling the “periodic” process to mine data can be efficiently done by choosing an appropriate storage system with efficient indexes. (MySQL/Postgres/Columnar-Storage/Cassandra etc etc)
* Did you run a database? Did it run as a separate tier in a different server?
3. A queue/scheduling framework which would trigger the data-processing in periodic intervals(like google app-engine cron service)
* How many “cron-entries” do you have in your system?
4. A CPU intensive algorithm which parses the incoming client’s data before persisting in the database.
* The incoming data from the client may require CPU intensive processing. (Example: parsing the data, eliminating duplicates etc etc). Did the CPU
shoot up because of this?
Will be great if you can throw some light on the volume/scale of the processing involved.
Would like to know what kind of work load is “Go” better than Ruby.
* Should I consider “Go” if I have lots of String (stream) processing to do?
* Should I consider “Go” for handling several concurrent sockets?
Would appreciate any help in understanding this.
You mention Java NIO, another point for Go!
I program in Java most of the time and I have done quite some Java NIO. (I still can’t program for Go professionally, most people in Spain does not even know or care it exists).
I used to like what NIO gave me in terms of control of events and reducing “unwanted” thread count… BUT that came with a BIG price tag:
1) Code was UGLY, UNNATURAL, REPETITIVE AND ERROR PRONE. Dealing with events means polling-detect event-call handler loops, enabling socket writes, en-queueing data before actually sending it, etc
Your code have to be totally different form the single threaded/sequential process, the natural way to program.
Not a big surprise that Java SSL has (or used to have) bad NIO support.
2) If you had one core, you could do everything NIO without firing any threads and probably get better performance… but when you have more than a core (which you almost ALWAYS have now) you are not using the power of the machine underneath.
With Go you have…
1) NIO without the ugly code: Channels (and I believe sockets too) work on (e)poll, in fact there is no other way for the Go runtime right now to evict a goroutine from a thread apart from when it “stops” by a syscall (send/receive, etc) So you are using NIO BUT you don’t need to poll-detect-handle, you don’t have to change your sequential code that much.
2) If you have more than 1 core, your just tell it so to the runtime, and it will put your goroutines all over them. (use GOMAXPROCS)
The design of the language encourages proper coding habits:
https://jmoiron.net/blog/whats-going-on/
Which webserver and backend protocol (cgi, fcgi, etc) did you used?
None, straight up Go.
Nice retrospective write up. Will definitely take another look at Go with fresh eyes.
The big takeaway here for anyone, is not to use Rails as an API. We use Rails everyday for a lot of things, but never for API’s. The stack is just too deep.
There are GREAT alternatives that are VERY VERY fast in ruby… such as Goliath.
https://github.com/postrank-labs/goliath
Goliath is perfect for API’s and is literally hundreds of times faster then rails doing the exact same thing. Even better, you stick with Ruby. And you don’t get the spaghetti code of Node.js
Did you consider using YBC ( https://github.com/valyala/ybc/tree/master/bindings/go/ybc ) as a library for in-process caching?
What made you reject Python in favor of Go?
I’d be really interested in knowing how you handled database access with Go. After working with Ruby for so long i find accessing the database directly with SQL queries to be ugly. While I understand its perfectly fine to do so it just makes the code so much harder to read with SQL statements scattered about? Could you speak a little about how you handled that? In that regards how did Eventmachine and Goliath compare with your assessment of Go?
Could you share some numbers about the Go’s performance:
– 99th, 95th percentile response latencies
– Effects of GC pauses
Yogi
So, let me get this straight.
You decided to make a service for internal use. Since Java is SO BORING, Platform and language were chosen by the ‘This is hype now!’ criteria. At production time it turned out, that your load balancer architecture causes cascade server failure during any load spike and your code is slow as hell. Because slow code can’t be caused by your ‘Hype’ programmers who produce great solutions like your load balancer, you decided that, of course, language is to blame. Your programmers proposed high load solutions like JS, but finally settled on something super exotic and not yet production proven – GO (‘Hype’ FTW!).
So you hired an actual good programmer, because there was no high demand for GO at that time and specialists were affordable, he rewrote your service, and it turned out, that you only needed 2 servers to do the job, instead of 32 that your previous specialists had so professionally estimated.
What can I say? Kudos for the GO programmers you hired, I suggest you keep them and fire the rest.
Hype?
I insist:
https://jmoiron.net/blog/whats-going-on/
Half the problems are bad cultural habits, most of them partly induced by the language constructs, and half are technical and unavoidable within that language.
Have you tried Go at all?
I have, and compared to my day to day Java, I can tell you, it is clearly an enhanced language. As I said before:
– Native UTF-8
– Less memory consumption
– Compiled
– Statically typed but with flexible interfaces, more flexible that any other typed language I’ve seen
– NIO without the pain
– structs vs hashes all around
– simple and light concurrency without the pain…
etc
Give it a try yourself before and then tell us if you really still think it’s just hype…
By the way, Two of the inventors of Go, Rob Pike and KEN THOMPSON are the guys that made finally possible (with UTF-8) that you can write your name here in Cyrillic chars and I can, at the same time in the same page, write “EspaÑa” without breaking the legacy Ascii completely.
Maybe the “hype” from the co-inventor of C and both inventors of UTF-8 deserves a little more respect… who knows! Maybe they know what they are doing…
😉
Sire, have you read my post? I actually suggested to the company to keep the GO guys and fire the rest. But my point is – their problem is with incompetent programmers and manager who wrote the original solution, not language.
>>”there were two really hot things at that time: Amazon Web Services and Ruby on Rails. So we built apps using Ruby on Rails on AWS”
Choosing an SUV because ‘they are hot things at the time’ is not very smart, but understandable. Choosing a platform because ‘it’s hot’ is downright stupid.
>>”When we first decided on Go, it was a risky decision…We also weren’t sure if we would be able hire top talent if we chose Go”
So, deciding to use GO when you actually don’t have specialists in GO. Answer me this, if the company doesn’t have a specialist in GO, how can it actually decide if GO is right for the task? The two above quotes make me think there is a big problem with managers and system architects in the company.
Finally, the whole idea of the post is a ludicrous success story. “We made a service that cost a fortune to run and still failed. So we hired a few guys who remade our service and now it runs ok.” If that is called success – than my company is ran by Gods, because we would call it “failure when you have to hire new people to clean up your mess”. And, BTW, GO is faster than Ruby, but it is not 15 times faster than Ruby!
P.S. Do you really think Java is not compiled before it is ran? Do you know what is a JITter and what it does? And if concurrency is ”a pain” for you – let me tell you, language is not to blame. And I’m not saying it because I am a fan of Java, I actually use C# (chose it, because it is technically superior by a magnitude) and Python (real open source). I’m just sick of carpenters who blame their hammer for the crappy bench they made.
That’s quite a load of assumptions you came up with there.
Yes I know what the JIT does, I program in Java most of the time…
JIT is Just in Time (compilation), Go is ALREADY compiled. there is quite a difference. And you should know it well, cause (I think) C# allowed you to select WHEN you wanted to have the code compiled for the target platform, doesn’t it? why should it do that if it didn’t matter?
The problem with your argument, though, is this sentence, in where you give yourself away and show that you are not coherent:
“…And I’m not saying it because I am a fan of Java, I actually use C# (chose it, because it is technically superior by a magnitude)”
See?
You assert here that C# is “technically superior to Java by a magnitude”, without giving any prove, and yet you are criticising Travis here for doing the same… well, not the same, he at least explains a case and gives some data to backup his case.
I am not going to argue with you on C#, and you know why not?
Cause I do not know C#. I have never programmed in C# and I don’t expect to do it shortly. Don’t get me wrong, I know some details of its design and they are cool, but the problem for ME is that its a Microsoft ONLY shop, and that does not interest me or my projects right now and on the short term future. (I am not arguing against it, just explaining why I don’t use it.)
As I don’t use, I don’t know it, so I CAN’T say it is NOT superior to Java, or Go or Ruby.
On the other side you don’t know Go, and you argue against Travis, who obviously knows it, THAT Go it’s not “a superior technical choice” than Ruby FOR THE CASE he explains here…
Travis NEVER said Ruby was rubbish,
if you allow me the rythme.
In fact Travis never was so BOLD as (you are) to say that Go was “technically superior by a magnitude” or x15 to Ruby, he just said Go was a far better choice for this use case than Ruby.
So basically I don’t know why are you complaining about!
[This is another example of the “funnel law” many people use, “wide for me, narrow for the rest”, Кошелев can say C# is much better that X without any prove while Travis is not allowed to say Go is better that Y for the case Z]
Sorry for the above long post, when I detect people incoherence and specially the “funnel law” at work, I can’t help myself… I have to point it out!
I learned Java back when I had to decide on my main production languages, around 2010. Back then I compared Java and C# and came to conclusion, that C# is far superior. But I gave it a try, before deciding not to use it. That is the main definition of not being a fanatic in my mind – you give something a try, and the outcome of the experiment actually determines your opinion. While this article https://en.wikipedia.org/wiki/Comparison_of_C_Sharp_and_Java speaks for itself, let me point out some of the key things that Java lacks: lambdas and LINQ (and the future promise of Reactive Extensions), ‘dynamic’ variable type and DLR analog, Task Parallelism Library analog (and async-await pattern from the recent C# 5). I used to think “Well, Java might have a few things missing, but it is still great, because it is Open Source” (yeah, I see the MS only drawback), but then Oracle sued Google and my faith in that argument was lost (but hey, it pushed me to learn the Joy of Python 🙂 ).
Now, regarding the JITter.
“Yes I know what the JIT does, I program in Java most of the time…
JIT is Just in Time (compilation), Go is ALREADY compiled. there is quite a difference.”
And what is the difference? You have a Web Service, you deploy the package, server detects a change in source code and runs the precompiler to refresh the compiled library that actually serves user requests. Yes, it has to take an additional 5-30 seconds every time you update the code or the server restarts (assuming, of course, the config admin for the server knew what he was doing and the service is constantly in hot state). The argument ‘byte code has to be compiled before use and that makes it slow’ is one of the worst myth to ever surround C# and Java. It happens 1 time, and after that it is the same machine code as any compiled language would give you, used for countless iterations. If anything – this compilation is a plus, because it gets compiled not for a whole line of CPU architecture, but for one particular CPU, which is fully known at compile time – no assumption about supported sets of instructions has to be made – so the machine code emitted can get the most of the actual CPU used.
I’m not a specialist in GO or Ruby, but I know a thing or two about the defining principles of computation and I stand by my point – you can’t get a 15 times speed increase just from changing the language. BTW, I actually went on to ask some of my colleagues, who are specialists in Ruby and have tried GO. They say you could achieve 2 – 4 times speed increase AT MOST from switching one to another.
I have to say I agree with almost all the points in this reply. 🙂
Again,
Is there is no difference, why does C# allows you to select to compile beforehand or at the end (JIT)?
Nobody talked about speed, although JIT compiling NEVER comes for free.
Distribution and deployment is one problem, sometimes you just don’t have or can assume there is a JIT compiler for your language in the target box, sometimes you can’t even assume the proper libs are installed in there either… those both are NON-ISSUES in PRE-compiled and statically linked Go.
Hi! Thanks for article – it’s very inspiring to learn something new! Right now I’m lookign to add something to my Rails/JS knowledge and scales fluctuate between Erlang and Go.
Can you give some more light on key points about choosing between two of those?
Also after brief look on Go I noticed dereference operator (‘*’)… How heavy is Go related to C?
I am also very interested in knowing what the reasons were for discarding Python, just out of curiosity… I am currently looking into building an API-centric webservice and am considering Python, but your article would almost make me want to try Go. So, if you can spare a few minutes, it will really help me.
Just for information, I am considering Python with use of greenlets for high concurrency support..
Hi — nowhere in the article do you say what the concurrency model was in your before or your after system.
If you moved from a process-based single-threaded concurrency model in ruby (which is the most common deployment) to a threaded or evented/reactor concurrency model in go, then that is probably the main source of the dramatic decrease in needed resources.
I’d love to see a competition where a server providing a restful JSON API must be built by the best practitioners for each platform. See who finishes first and see which solution can handle the most traffic with equivalent hardware.
@Alan Brown, so much yes!
Thank U for this nice blog, It’s very beneficial for All . Find More Job Vacancies here – Visit Here
Is your API similar to https://www.codementor.io/codehakase/building-a-restful-api-with-golang-a6yivzqdo? Or can you provide some code samples?
Chris! Both IronWorker and IronMQ do have HTTP API’s. Are you curious as to what libraries we use internally?