
Web Crawling at Scale with Nokogiri and IronWorker (Part 2)

This is the second part of a two-part post on using IronWorker with Nokogiri to do web crawling at scale. The first blog post can be viewed here.
Other resources for web crawling can be seen on our solutions page as well as this post on using IronWorker with PhantomJS.
Distributed Web Crawling
Crawling web sites is core to many web-based businesses – whether it’s monitoring prices on retail sites, analyzing sentiment in posts and reports, vetting SEO metrics for client sites,
or any number of other purposes. In the first post, we addressed how to use IronWorker with Nokogiri to perform web crawling and page processing in a distributed way. This post will add in a few more components – namely message queues and key/value caches – to make it even easier to crawl sites in a highly distributed and scalable manner.
Breaking Work into Discrete Tasks and Workload Units
The core part of performing any type of work at scale is to break the work into discrete tasks and workload units. This allows the workload to be distributed easily across a set of servers. Monolithic architectures and tight bindings between processes make it difficult to move the work to elastic distributed environments.
In the case of web crawling, breaking the work up involves creating workers for specific tasks – in the base case, one worker to crawl and collect pages from sites and another worker to pull out specific page attributes from the pages.
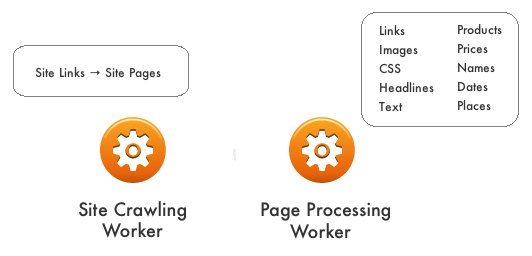 |
| Separate Workers – Separate Functions |
The other part of the process – the distribution of work across a cloud infrastructure – is where a task queue or worker system comes in. A task queue can either slot into an application as a scale component or it can be a stand-alone middleware layer within a distributed cloud-based system. In the case of the latter, different applications or triggers are queuing up tasks instead of a single application. A task queue – like Iron.io’s IronWorker service – manages the provisioning of resources and monitoring and distribution of jobs across a large set of servers. Developers just need to worry about creating and initiating tasks and the task queue performs the overhead of distributing and executing the tasks.
Tightly Coupled Workers → Reduced Agility
In a model where one worker performs one task and then passes work off to another, it’s certainly possible to have the first worker queue one or more instances of the second worker. This is a simple way to handle things and is generally fine for limited flows and modest workloads.
The problem with directly chaining workers together, however, is that it doesn’t expand all that well. For example, some resources might be rate limited or have certain thresholds, so a large number of concurrent workers will run up against these limits. In these situations, the workers might have to have the intelligence to manage the state of the operation. This means additional overhead and a more brittle architecture. Also, given that worker tasks should ideally be finite in nature (there’s a 60-minute time limit for tasks in IronWorker), this means added overhead to maintain state.
Max Concurrency: Setting Limits on Number of Parallel Workers
When queuing from the CLI, you would include the –max-concurrency argument with a value as part of the upload. And so if your worker is called WebCrawlerWorker and you had a worker_name.worker file called web_crawler_worker.worker, you would upload like this:
iron_worker upload web_crawler_worker –max-concurrency 50
Using Message Queues and Data Caches to Orchestrate Many Tasks
A better way is to orchestrate and coordinate large sets of connected tasks is to use message queues and key/value data caches. A message queue is used as a layer or broker between tasks. One process puts a message on a queue and another takes it off, making it so that each worker is independent of any other worker. This structure also lets each part of the processing scale independently. The tasks perform their work, put messages on a queue for other workers, and then can expire, all without causing any conflict with other parts of the process. (See the blog post on Spikability for more information on how applications can better handle unknown and/or inconsistent load.)
Adding a new task or step within the process is as simple as adding a new queue and then putting messages on the queue. A new worker can then take the messages off the queue and do the processing that it needs to do. An analogy might be to Unix pipe, where the results of one command are piped to another command – each command with a defined interface independent of any other commands.
![]() A key/value data cache is used to share data between tasks, store temporary processing results, and maintain global counters and variables. It simplifies the process by reducing the need to use a database for temporary or transient data. Instead of having to open and maintain database connections and wrestle with schemas, developers can just simple http requests to post key/value pairs for other workers to access. This is akin to shared memory space although instead of within a single machine, it’s at a cloud level, accessible via HTTP requests and supporting many concurrent processes across thousands of independent cores.
A key/value data cache is used to share data between tasks, store temporary processing results, and maintain global counters and variables. It simplifies the process by reducing the need to use a database for temporary or transient data. Instead of having to open and maintain database connections and wrestle with schemas, developers can just simple http requests to post key/value pairs for other workers to access. This is akin to shared memory space although instead of within a single machine, it’s at a cloud level, accessible via HTTP requests and supporting many concurrent processes across thousands of independent cores.
Putting Messages on a Queue
In the web crawling example we’ve created, the site crawling worker grabs each page link, puts it in a message, and then places it in a queue in IronMQ. Worker processes on the receiving end take the messages off the queue and process the page links. In this Nokogiri crawling example, the page processing worker will process a 100 pages at a time.

Example Repo: Web Crawler – Nokogiri
Filename: web_crawler.rb (excerpt)
def process_page(url)
puts “Processing page #{url}”
#adding url to cache
@iron_cache_client.items.put(CGI::escape(url), {:status => “found”}.to_json)
#pushing url to iron_mq to process page
result = @iron_mq_client.messages.post(CGI::escape(url))
puts “Message put in queue #{result}”
end
def crawl_domain(url, depth)
#…
#getting page from cache
page_from_cache = @iron_cache_client.items.get(CGI::escape(page_url))
if page_from_cache.nil?
#page not processed yet so lets process it and queue worker if possible
process_page(page_url) if open_url(page_url)
queue_worker(depth, page_url) if depth > 1
else
puts “Link #{page_url} already processed, bypassing”
#page_from_cache.delete
end
#…
end
Getting and Deleting Messages
The page processor worker gets multiple messages from the queue (get operations in IronMQ can retrieve many messages at once). These are then processed in a loop.
The message delete occurs after the message is fully processed. This is done instead of deleting the messages right after the ‘get’ operation so that if the worker fails for some reason, any unprocessed messages will automatically get put back on the queue for processing by another task.
Note that we use a cache to check if the URL has been processed (more details below).
Filename: page_processor.rb (excerpt)
def get_list_of_messages
#100 pages per worker at max
max_number_of_urls = 100
puts “Getting messages from IronMQ”
messages = @iron_mq_client.messages.get(:n => max_number_of_urls, :timeout => 100)
puts “Got messages from queue – #{messages.count}”
messages
end
#getting list of urls
messages = get_list_of_messages
#processing each url
messages.each do |message|
url = CGI::unescape(message.body)
#getting page details if page already processed
cache_item = @iron_cache_client.items.get(CGI::escape(url))
if cache_item
process_page(url)
else
increment_counter(url, cache_item)
end
message.delete
end
Using a Key/Value Data Cache
A key/value data cache is equally as valuable as a message queue in terms separating work and orchestrating asynchronous flow. A flexible data cache lets asynchronous processes leave data for others to act on along with exchanging state between a set of stateless processes.
A key/value data cache is different than a database in that it is meant less as a permanent data store (although data can persist indefinitely) but more as a data store for transitional activity. A data cache is particularly well-suited to storing, retrieving, and deleting data, but it doesn’t have the searching and scanning functions of an SQL or even NoSQL database.
In the case of web crawling, a cache can be used:
- to store page links – especially ones have been processed so that other page processors can check the cache to avoid crawling the same page.
- to store the page object collected by the site crawler
- to store intermediate results of page processing – results that might need to be processed by other types of workers.
- to store counters for number of workers currently crawling a site – as a manual way to limit workers (instead of the max_concurrency feature)
- to store global counters, timing results, and other activity, much of which can later be stored to preserve an activity log of the crawling operation.
In a more expanded version of the page parsing loop, the data that’s collected gets placed in the cache for further processing. The choice of key – the URL – is an arbitrary choice here. Other keys can be used, even multiple items can be stored – one for each value for example.
def process_page(url)
puts “Processing page #{url}”
doc = Nokogiri(open(url))
images, largest_image, list_of_images = process_images(doc)
#processing links an making them absolute
links = process_links(doc).map { |link| make_absolute(link[‘href’], url) }.compact
css = process_css(doc)
words_stat = process_words(doc)
puts “Number of images on page:#{images.count}”
puts “Number of css on page:#{css.count}”
puts “Number of links on page:#{links.count}”
puts “Largest image on page:#{largest_image}”
puts “Words frequency:#{words_stat.inspect}”
#putting all in cache
@iron_cache_client.items.put(CGI::escape(url), {:status => “processed”,
:number_of_images => images.count,
:largest_image => CGI::escape(largest_image),
:number_of_css => css.count,
:number_of_links => links.count,
:list_of_images => list_of_images,
:words_stat => words_stat,
:timestamp => Time.now,
:processed_counter => 1}.to_json)
end
def increment_counter(url, cache_item)
puts “Page already processed, so bypassing it and incrementing counter”
item = JSON.parse(cache_item)
item[“processed_counter”]+=1 if item[“processed_counter”]
@iron_cache_client.items.put(CGI::escape(url), item.to_json)
end
Extending the Example
In this Nokogiri example, there’s one queue and one type of page processing worker. Using multiple IronMQ queues and one or more IronCache caches, it’s easy to extend the work and do even more sophisticated processing flows. For example, if a page needed to be processed in two different ways, two queues could be used, each with different workers operating on messages in the queue. If more extensive things need to happen to the data that’s collected, another queue could be added in the chain. The chain could extend as long as necessary to perform the work that’s needed.
The beauty of this approach is that developers can focus on creating simple focused tasks that do a few things well and then pass the work off to other tasks. Log files are isolated and task specific. Any changes that are made in one task are less likely to spill over to other parts in the chain. Any errors that occur therefore take place within a small range of possibilities, making it easier to isolate.
All in all, the system is easier to build, easier to scale, easier to monitor, and easier to maintain. All by adding task queues, message queues, data caches, and job scheduling that work in a distributed cloud environment.
With these type of elastic cloud components, it’s easy to break the chains of monolithic apps that make use of a limited set of servers, and take advantage of reliable distributed processing at scale. What’s not to love?
Resources
For a deeper look at web crawling at scale, take a look at the example at the link below.
Example Repo: Web Crawler – Nokogiri
For more information on Nokogiri check out these tutorials here, here, and here and a great RailsCast here.
Special Credits
