
How HotelTonight uses Iron.io and AWS Redshift to create Ruby-based ETL pipeline (repost)
 |
| Creating an ETL pipeline with Iron.io and Redshift |
Operating at scale in the cloud almost always equates to having a highly distributed system architecture in place to handle workloads by auto-scaling components out horizontally
Harlow Ward is a developer at HotelTonight and he put together a great post on how they handle issues of scale. In it he talks about their use of Iron.io and Amazon's Redshift offering to create a simple highly scalable ETL pipeline.
Here's an excerpt from his article.
As the data requirements of our Business Intelligence team grow, we’ve been leveraging Iron.io’s IronWorker as our go-to platform for scheduling and running our Ruby-based ETL (Extract, Transform, Load) worker pipeline.
Business units within HotelTonight collect and store data across multiple external services. The ETL pipeline is responsible for gathering all the external data and unifying it into Amazon’s excellent Redshift offering.
Redshift hits a sweet spot for us as it uses familiar SQL query language, and supports connections from any platform using a Postgres adapter.
This allows our Ruby scripts to connect with the PG Gem, our Business Intelligence team to connect with their favorite SQL Workbench, and anyone in our organization with Looker access to run queries on the data.
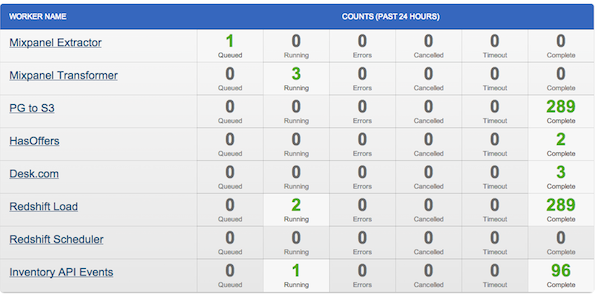 |
| HotelTonight's Dashboard of Workers |
The team at Iron.io have been a great partner for us while building the ETL pipeline. Their worker platform gives us a quick and easy mechanism for deploying and managing all our Ruby workers.
The administration area boasts excellent dashboards for reporting worker status and gives us great visibility over the current state of our pipeline.
––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––––
About the Author/Developer

Harlow Ward is a developer at HotelTonight. Prior to that, he was at thoughtbot (creators of Paperclip, Factory Girl, Shoulda, Airbrake, and more). He's co-author of "Ruby Science," and enjoys writing technical articles focused on sharing development techniques throughout the community. (@futuresanta)